I make websites. Sometimes I make music. Over the years, I’ve noticed an
interesting pattern of behavior from some musicians—often self-taught—who
think of themselves as creative types: they display an aversion to
learning any music theory. The logic, they say, is that knowing the theory
behind music will somehow constrain their creative abilities. I’ve never
understood that logic (and I secretly believe that it’s a retroactive
excuse for a lack of discipline). To my mind, I just don’t see how any
kind of knowledge or enlightenment could be a bad thing.
Alas, I have seen the same kind of logic at work in the world of web
design. There are designers who not only don’t know how to write markup
and CSS, they actively refuse to learn. Again, they cite the fear of
somehow being constrained by this knowledge (and again, I believe that’s a
self-justifying excuse).
In the world of front-end development, that attitude is fortunately far
less prevalent. Most web devs understand that there’s always more to
learn. But even amongst developers who have an encyclopediac knowledge of
HTML and CSS, there is often a knowledge gap when it comes to the Document
Object Model. That’s understandable. You don’t need to understand the
inner workings of the DOM if you’re using a library like jQuery. The whole
point of JavaScript libraries is to abstract away the browser’s internal
API and provide a different, better API instead.
Nonetheless, I think that many front-end devs have a feeling that they
should know what’s going on under the hood. That’s the natural reaction of
a good geek when presented with a system they’re expected to work with.
Now, thanks to DOM Enlightenment, they can scratch that natural itch.
Douglas Crockford gave us a map to understand the inner workings of the
JavaScript language in his book JavaScript: The Good Parts. Now Cody
Lindley has given us the corresponding map for the Document Object Model.
Armed with this map, you’ll gain the knowledge required to navigate the
passageways and tunnels of the DOM. ix
You might not end up using this knowledge in every project. You might
decide to use a library like jQuery instead. But now it will be your
decision. Instead of having to use a library because that’s all that you
know, you can choose if and when to use a library. That’s a very
empowering feeling. That’s what knowledge provides. That is true
enlightenment.
—Jeremy Keith, founder and technical director of clearleft.com, and
author of DOM Scripting: Web Design with JavaScript and the Document
Object Model
Introduction
This book is not an exhaustive reference on DOM scripting or
JavaScript. It may,
however, be the most exhaustive book written about DOM scripting without
the use of a library/framework. The lack of authorship around this topic
is not without good reason. Most technical authors are not willing to
wrangle this topic because of the differences that exist among legacy
browsers and their implementations of the DOM specifications (or lack
thereof).
For the purpose of this book (i.e. grokking the concepts), I'm going to
sidestep the browser API mess and dying browser discrepancies in an effort
to expose the modern DOM. That's right, I'm going to sidestep the ugliness
in an effort to focus on the here and now. After all, we have solutions
like jQuery to deal with all that browser ugliness, and you should
definitely be leveraging something like jQuery when dealing with
deprecated browsers.
While I am not promoting the idea of only going native when it comes to
DOM scripting, I did write this book in part so that developers may
realize that DOM libraries are not always required when scripting the DOM.
I also wrote for the lucky few who get to write JavaScript code for a
single environment (i.e. one browser, mobile browsers, or
HTML+CSS+JavaScript-to-native via something like PhoneGap). What you learn
in this book may just make a DOM library unnecessary in ideal situations,
say for example, some light DOM scripting for deployment on a Webkit
mobile browser only.
Who should read this book
As I authored this book, I specifically had two types of developers in
mind. I assume both types already have an intermediate to advanced
knowledge of JavaScript, HTML, and CSS. The first developer is someone who
has a good handle on JavaScript or jQuery, but has really never taken the
time to understand the purpose and value of a library like jQuery (the
reason for its rhyme, if you will). Equipped with the knowledge from this
book, that developer should fully be able to understand the value provided
by jQuery for scripting the DOM. And not just the value, but how jQuery
abstracts the DOM and where and why jQuery is filling the gaps. The second
type of developer is an engineer who is tasked with scripting HTML
documents that will only run in modern browsers or that will get ported to
native code for multiple OS's and device distributions (e.g. PhoneGap) and
needs to avoid the overhead (i.e. size or size v.s. use) of a library.
Technical intentions, allowances, & limitations
The content and code contained in this book was written with modern
(IE9+, Firefox latest, Chrome latest, Safari latest, Opera latest)
browsers in mind. It was my goal to only include concepts and code that
are native to modern browsers. If I venture outside of this goal I will
bring this fact to the readers attention. I've generally steered away
from including anything in this book that is browser specific or
implemented in a minority of the modern browsers.
I'm covering several hand picked topics that are not DOM specific. I've
included these topics in this book to help the reader build a proper
understanding of the DOM in relationship to CSS and JavaScript.
I've purposely left out any details as it pertains to XML or XHTML.
I've purposely excluded the form and table api's to keep the book small.
But I can see these sections being added in the future.
O'Reilly will release and sell a hard
copy & eBook in the near future.
Preface
Before you begin, it is important to understand various styles employed in
this book. Please do not skip this section, because it contains important
information that will aid you in the unique styles of this book.
This book is not like other programming books
The enlightenment series (jQuery Enlightenment &
JavaScript Enlightenment) is written in a style that favors small, isolated, immediately
executable code over wordy explanations and monolithic programs. One of my
favorite authors, C.S Lewis, asserts that words are the lowest form of
communication that humans traffic in. I totally agree with this assertion
and use it as the basis for the style of these books. I feel that
technical information is best covered with as few words as possible, in
conjunction with just the right amount of executable code and commenting
required to express an idea. The style of this book attempts to present a
clearly defined idea with as few words as possible, backed with real code.
Because of this, when you first start grokking these concepts, you should
execute and examine the code, thereby forming the foundation of a mental
model for the words used to describe the concepts. Additionally, the
format of these books attempts to systematically break ideas down into
their smallest possible form and examine each one in an isolated context.
All this to say that this is not a book with lengthy explanations or
in-depth coverage on broad topics. Consider yourself warned. If it helps,
think of it as a cookbook, but even more terse and to the point than
usual.
Color-coding conventions
In the code examples (example shown below), orange is used to highlight
code directly relevant to the concept being discussed. Any additional code
used to support the orange colored code will be green. The color gray in
the code examples is reserved for comments.
<!DOCTYPE html>
<html lang="en">
<body>
<script>
// this is a comment about a specific part of the code var foo = 'calling out this part of the code';
</script>
</body>
</html>
jsFiddle
The majority of code examples in this book are linked to a corresponding
jsFiddle page, where the code can be
tweaked and executed online. The jsFiddle examples have been configured to
use the
Firebug lite-dev plugin
to ensure the reader views the console.log prevalent in this book. Before
reading this book, make sure you are comfortable with the usage and
purpose of console.log.
In situations where jsFiddle caused complications with the code example, I
simply chose not to link to a live example.
About the Author
Cody Lindley is a client-side
engineer (aka front-end developer) and recovering Flash developer. He has
an extensive background working professionally (11+ years) with HTML, CSS,
JavaScript, Flash, and client-side performance techniques as it pertains
to web development. If he is not wielding client-side code he is likely
toying with interface/interaction design or authoring material and
speaking at various conferences. When not sitting in front of a computer,
it is a sure bet he is hanging out with his wife and kids in Boise, Idaho
– training for triathlons, skiing, mountain biking, road biking, alpine
climbing, reading, watching movies, or debating the rational evidence for
a Christian worldview.
Table of Contents
Chapter 1 - Node Overview
1.1 The Document Object Model (aka the DOM) is a hierarchy/tree of
JavaScript node objects
When you write an HTML document you encapsulate HTML content inside of
other HTML content. By doing this you setup a hierarchy that can be
expressed as a
tree. Often this hierarchy or encapsulation system is indicated visually by
indenting markup in an HTML document. The browser when loading the HTML
document interrupts and
parses this hierarchy to create a tree of node objects
that simulates how the markup is encapsulated.
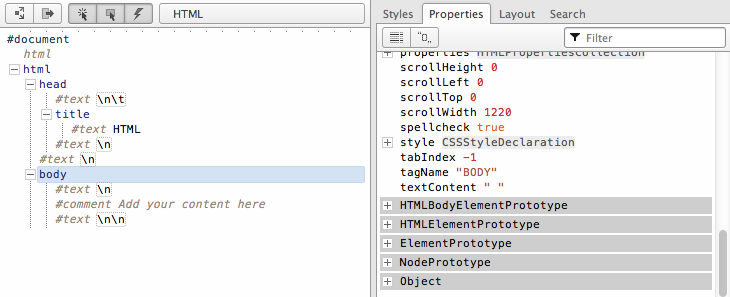
The above HTML code when parsed by a browser creates a document that
contains nodes structrured in a tree format (i.e. DOM). Below I reveal
the tree struture from the above HTML document using Opera's Dragonfly
DOM inspector.
On the left you see the HTML document in its tree form. And on the right
you see the corresponding JavaScript object that represents the selected
element on the left. For example, the selected
<body> element highlighted in blue, is an element node
and an instance of the HTMLBodyElement interface.
What you should take away here is that html documents get parsed by a
browser and converted into a tree structure of node objects representing
a live document. The purpose of the DOM is to provide a programatic
interface for scripting (removing, adding, replacing, eventing,
modifiying) this live document using JavaScript.
Notes
The DOM originally was an application programming interface for XML
documents that has been extended for use in HTML documents.
1.2 Node object types
The most common (I'm not highlighting all of them in the list below)
types of nodes (i.e. nodeType/node classifications) one
encounters when working with HTML documents are listed below.
I've listed the node types above formatted (all uppercase with _
separating words) exactly as the constant property is written in the
JavaScript browser environment as a property of the
Node object. These Node properties are constant values
and are used to store numeric code values which map to a specific type
of node object. For example in the following code example,
Node.ELEMENT_NODE is equal to 1. And 1 is the
code value used to identify element nodes.
<!DOCTYPE html>
<html lang="en">
<body>
<script>
console.log(Node.ELEMENT_NODE) //logs 1, one is the numeric code value for element nodes
</script>
</body>
</html>
In the code below I log all of the node types and there values.
The previous code example gives an exhaustive list of all node types.
For the purpose of this book I'll be discussing the shorter list of node
types listed at the start of this section. These nodes will most likely
be the ones you come in contact with when scripting an HTML page.
In the table below I list the name given to the interface/constructor
that instantiates the most common node types and their corresponding
nodeType classification by number and name. What I hope you
take away from the table below is the nodeType value (i.e.
1) is just a numeric classificaiton used to describe a certain
type of node constructed from a certain JavaScript
interface/constructor. For example, the
HTMLBodyElement interface reprsents a node object that has a
node type of 1, which is a classification for
ELEMENT_NODE's.
The DOM specification semantically labels nodes like Node,
Element, Text, Attr, and
HTMLAnchorElement as an interface, which it is, but keep in
mind its also the name given to the JavaScript constructor function
that constructs the nodes. As you read this book I will be referring
to these interfaces (i.e. Element, Text,
Attr, HTMLAnchorElement) as objects or constructor
functions while the specification refers to them as interfaces.
The ATTRIBUTE_NODE is not actually part of a tree but listed
for historical reasons. In this book I do not provide a chapter on
attribute nodes and instead discuss them in the Element node
chapter given that attributes nodes are sub-like nodes of element
nodes with no particiipation in the actual DOM tree structure. Be
aware the ATTRIBUTE_NODE is being depreciated in DOM 4.
I've not included detail in this book on the COMMENT_NODE but
you should be aware that comments in an HTML document are
Comment nodes and similar in nature to Text nodes.
As I discuss nodes throughout the book I will rarely refer to a
specific node using its nodeType name (e.g.
ELEMENT_NODE). This is done to be consistent with verbiage
used in the specifications provided by the W3C & WHATWG.
1.3 Sub-node objects inherit from the Node object
Each node object in a typical DOM tree inherits properties and methods
from Node. Depending upon the type of node in the document
there are also additional sub node object/interfaces that extend the
Node object. Below I detail the inheritance model implemented
by browsers for the most common node interfaces (< indicates
inherited from).
Object < Node < Element <
HTMLElement < (e.g. HTML*Element)
Object <Node <
Attr (This is deprecated in DOM 4)
Object <Node <
CharacterData < Text
Object <Node <
Document < HTMLDocument
Object <Node <
DocumentFragment
Its important not only to remember that all nodes types inherit from
Node but that the chain of inheritance can be long. For
example, all HTMLAnchorElement nodes inherit properties and
methods from HTMLElement, Element, Node, and
Object objects.
Notes
Node is just a JavaScript constructor function. And so
logically Node inherits from Object.prototype just
like all objects in JavaScript
To verify that all node types inherit properties & methods from the
Node object lets loop over an Element node object and
examine its properties and methods (including inherited).
<!DOCTYPE html>
<html lang="en">
<body>
<a href="#">Hi</a> <!-- this is a HTMLAnchorElement which inherits from... -->
<script>
//get reference to element node object
var nodeAnchor = document.querySelector('a');
//create props array to store property keys for element node object
var props = [];
//loop over element node object getting all properties & methods (inherited too)
for(var key in nodeAnchor){
props.push(key);
}
//log alphabetical list of properties & methods
console.log(props.sort());
</script>
</body>
</html>
If you run the above code in a web browser you will see a long list of
properties that are available to the element node object. The properties
& methods inherited from the Node object are in this list
as well as a great deal of other inherited properties and methods from
the Element, HTMLElement, HTMLAnchorElement,
Node, and Object object. Its not my point to examine
all of these properties and methods now but simply to point out that all
nodes inherit a set of baseline properties and methods from its
constructor as well as properties from the prototype chain.
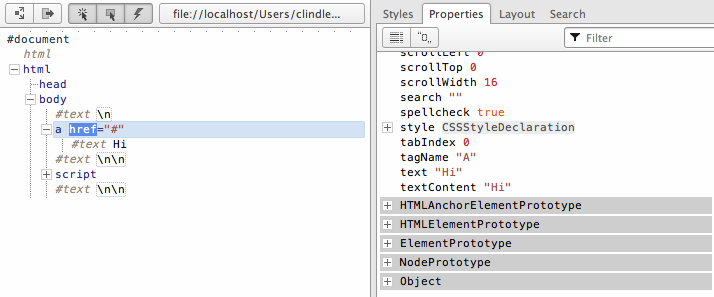
If you are more of visual learner consider the inheritance chain denoted
from examining the above HTML document with Opera's DOM inspector.
Notice that the anchor node inherits from HTMLAnchorElement,
HTMLElement, Element, Node, and
Object all shown in the list of properties highlighted with a
gray background. This inheritance chain provides a great deal of shared
methods and properties to all node types.
Like we have been discussing all node objects (e.g Element,
Attr, Text etc...) inherit properties and methods from
a primary Node object. These properties and methods are the
baseline values and functions for manipulating, inspecting, and
traversing the DOM. In addtion to the properties and methods provided by
the node interface there are a great deal of other relevant properties
and methods that are provided by sub node interfaces such as the
document, HTMLElement, or
HTML*Element interface.
Below I list out the most common Node properties and methods
inherited by all node objects including the relevant inherited
properties for working with nodes from sub-node interfaces.
Node Properties:
childNodes
firstChild
lastChild
nextSibling
nodeName
nodeType
nodeValue
parentNode
previousSibling
Node Methods:
appendChild()
cloneNode()
compareDocumentPosition()
contains()
hasChildNodes()
insertBefore()
isEqualNode()
removeChild()
replaceChild()
Document Methods:
document.createElement()
document.createTextNode()
HTML * Element Properties:
innerHTML
outerHTML
textContent
innerText
outerText
firstElementChild
lastElementChild
nextElementChild
previousElementChild
children
HTML element Methods:
insertAdjacentHTML()
1.5 Identifying the type and name of a node
Every node has a nodeType and nodeName property that
is inherited from Node. For example Text nodes have a
nodeType code of 3 and nodeName value of
'#text'. As previously mentioned the numeric value
3 is a numeric code representing the type of underlying object
the node represents (i.e. Node.TEXT_NODE === 3).
Below I detail the values returned for nodeType and
nodeName for the node objects discussed in this book. It makes
sense to simply memorize these numeric code's for the more common nodes
given that we are only dealing with 5 numeric codes.
<!DOCTYPE html>
<html lang="en">
<body>
<a href="#">Hi</a>
<script>
//This is DOCUMENT_TYPE_NODE or nodeType 10 because Node.DOCUMENT_TYPE_NODE === 10
console.log(
document.doctype.nodeName, //logs 'html' also try document.doctype to get <!DOCTYPE html>document.doctype.nodeType//logs 10 which maps to DOCUMENT_TYPE_NODE
);
//This is DOCUMENT_NODE or nodeType 9 because Node.DOCUMENT_NODE === 9
console.log(
document.nodeName, //logs '#document'document.nodeType //logs 9 which maps to DOCUMENT_NODE
);
//This is DOCUMENT_FRAGMENT_NODE or nodeType 11 because Node.DOCUMENT_FRAGMENT_NODE === 11
console.log(
document.createDocumentFragment().nodeName, //logs '#document-fragment'document.createDocumentFragment().nodeType//logs 11 which maps to DOCUMENT_FRAGMENT_NODE
);
//This is ELEMENT_NODE or nodeType 1 because Node. ELEMENT_NODE === 1
console.log(
document.querySelector('a').nodeName, //logs 'A'document.querySelector('a').nodeType//logs 1 which maps to ELEMENT_NODE
);
//This is TEXT_NODE or nodeType 3 because Node.TEXT_NODE === 3
console.log(
document.querySelector('a').firstChild.nodeName, //logs '#text'document.querySelector('a').firstChild.nodeType//logs 3 which maps to TEXT_NODE
);
</script>
</body>
</html>
If its not obvious the fastest way to determine if a node is of a
certain type is too simply check its nodeType property. Below
we check to see if the anchor element has a node number of 1. If it does
than we can conclude that its an Element node because
Node.ELEMENT_NODE === 1.
<!DOCTYPE html>
<html lang="en">
<body>
<a href="#">Hi</a>
<script>
//is <a> a ELEMENT_NODE?
console.log(document.querySelector('a').nodeType === 1); //logs true, <a> is an Element node//or use Node.ELEMENT_NODE which is a property containg the numerice value of 1
console.log(document.querySelector('a').nodeType === Node.ELEMENT_NODE); //logs true, <a> is an Element node
</script>
</body>
</html>
Determining the type of node that you might be scripting becomes very
handy so that you might know which properties and methods are available
to script the node.
Notes
The values returned by the nodeName property vary according
to the node type. Have a look at the
DOM 4 specification
provided for the details.
1.6 Getting a nodes value
The nodeValue property returns null for most of the
node types (except Text, and Comment). It's use is
centered around extracting actual text strings from Text and
Comment nodes. In the code below I demonstrate its use on all
the nodes discussed in this book
<!DOCTYPE html>
<html lang="en">
<body>
<a href="#">Hi</a>
<script>
//logs null for DOCUMENT_TYPE_NODE, DOCUMENT_NODE, DOCUMENT_FRAGMENT_NODE, ELEMENT_NODEbelow
console.log(document.doctype.nodeValue);
console.log(document.nodeValue);
console.log(document.createDocumentFragment().nodeValue);
console.log(document.querySelector('a').nodeVale);
//logs string of text
console.log(document.querySelector('a').firstChild.nodeValue); //logs 'Hi'
</script>
</body>
</html>
Notes
Text or Comment node values can be set by providing
new strings values for the nodeValue property(i.e.
document.body.firstElementChild.nodeValue = 'hi').
1.7 Creating element and text nodes using JavaScript methods
When a browser parses an HTML document it constructs the nodes and tree
based on the contents of the HTML file. The browser deals with the
creation of nodes for the intial loading of the HTML document. However
its possible to create your own nodes using JavaScript. The following
two methods allow us to programatically create Element and
Text nodes using JavaScript.
createElement()
createTextNode()
Other methods are avaliable but are not commonly used (e.g.
createAttribute() and createComment()) . In the code
below I show how simple it is to create element and text nodes.
<!DOCTYPE html>
<html lang="en">
<body>
<script>
var elementNode = document.createElement('div');
console.log(elementNode, elementNode.nodeType); //log <div> 1, and 1 indicates an element node
var textNode = document.createTextNode('Hi');
console.log(textNode, textNode.nodeType); //logs Text {} 3, and 3 indicates a text node
</script>
</body>
</html>
Notes
The createElement() method accepts one parameter which is a
string specifying the element to be created. The string is the same
string that is returned from the tagName property of an
Element object.
The createAttribute() method is depricated and should not be
used for creating attribute nodes. Instead developers typically use
getAttribute(), setAttribute(), and
removeAttribute() methods. I will discus this in more detail
in the Element node chapter.
The createDocumentFragment() will be discussed in the chapter
covering this method.
You should be aware that a createComment() method is
available for creating comment nodes. Its not discussed in this book
but is very much available to a developer who finds its usage
valuable.
1.8 Creating and adding element and text nodes to the DOM using
JavaScript strings
The innerHTML, outerHTML, textContent and
insertAdjacentHTML() properties and methods provide the
functionality to create and add nodes to the DOM using JavaScript
strings.
In the code below we are using the innerHTML,
outerHTML, and textContent properties to create nodes
from JavaScript strings that are then immediately added to the DOM.
<!DOCTYPE html>
<html lang="en">
<body>
<div id="A"></div>
<span id="B"></span>
<div id="C"></div>
<div id="D"></div>
<div id="E"></div>
<script>
//create a strong element and text node and add it to the DOM
document.getElementById('A').innerHTML = '<strong>Hi</strong>';
//create a div element and text node to replace <span id="B"></div> (notice span#B is replaced)
document.getElementById('B').outerHTML = '<div id="B" class="new">Whats Shaking</div>'
//create a text node and update the div#C with the text node
document.getElementById('C').textContent = 'dude';
//NON standard extensions below i.e. innerText & outerText//create a text node and update the div#D with the text node
document.getElementById('D').innerText = 'Keep it';
//create a text node and replace the div#E with the text node (notice div#E is gone) document.getElementById('E').outerText = 'real!';
console.log(document.body.innerHTML);
/* logs
<div id="A"><strong>Hi</strong></div>
<div id="B" class="new">Whats Shaking</div>
<span id="C">dude</span>
<div id="D">Keep it</div>
real!
*/
</script>
</body>
</html>
The insertAdjacentHTML() method which only works on
Element nodes is a good deal more precise than the previously
mentioned methods. Using this method its possible to insert
nodes before the beginning tag, after the beginning tag, before the end
tag, and after the end tag. Below I construct a sentence using the
insertAdjacentHTML() method.
The innerHTML property will convert html elements found in
the string to actual DOM nodes while the textContent can only
be used to construct text nodes. If you pass textContent a
string containing html elements it will simply spit it out as text.
document.write() can also be used to simultaneously create
and add nodes to the DOM. However its typically not used anymore
unless its usage is required to accomplish 3rd party scripting tasks.
Basically the write() method will output the values passed to
it into the page during page loading/parsing. You should be aware that
using the write() method will stall/block the parsing of the
html document being loaded.
innerHTML invokes a heavy & expensive HTML parser where
as text node generation is trivial thus use the innerHTML &
friends sparingly
The insertAdjacentHTML options "beforebegin" and "afterend"
will only work if the node is in the DOM tree and has a parent
element.
Support for outerHTML was not available natively in Firefox
until version 11. A
polyfill is avaliable.
textContent gets the content of all elements,
including <script> and <style> elements, innerText
does not
innerText is aware of style and will not return the text of
hidden elements, whereas textContent will
Avaliable to all modern browser except Firefox is
insertAdjacentElement() and insertAdjacentText()
1.9 Extracting parts of the DOM tree as JavaScript strings
The same exact properties (innerHTML, outerHTML,
textContent) that we use to create and add nodes to the DOM can
also be used to extract parts of the DOM (or really the entire DOM) as a
JavaScript string. In the code example below I use these properties to
return a string value containing text and html values from the HTML
document.
console.log(document.getElementById('A').outerHTML); //logs <div id="A">Hi</div>//notice that all text is returned even if its in child element nodes (i.e. <strong> !</strong>)
console.log(document.getElementById('B').textContent); //logs 'Dude !'//NON standard extensions below i.e. innerText & outerText
console.log(document.getElementById('B').innerText); //logs 'Dude !'
The textContent, innerText,
outerText property when being read will return all of the
text nodes contained within the selected node. So for example (not a
good idea in practice), document.body.textContent will get
all the text nodes contained in the body element not just the first
text node.
1.10 Adding node objects to the DOM using appendChild()&
insertBefore()
The appendChild() and insertBefore()Node methods allow us to insert JavaScript node objects into
the DOM tree. The appendChild() method will append a node(s) to
the end of the child node(s) of the node the method is called on. If
there are no child node(s) then the node being appended is appended as
the first child. For example in the code below we are creating a
element node (<strong>) and text node (Dude).
Then the <p> is selected from the DOM and our
<strong> element is appended using
appendChild(). Notice that the <strong> element
is encapsulated inside of the <p> element and added as
the last child node. Next the <strong> element is
selected and the text 'Dude' is appended to the
<strong> element.
<!DOCTYPE html>
<html lang="en">
<body>
<p>Hi</p>
<script>
//create a blink element node and text node
var elementNode = document.createElement('strong');
var textNode = document.createTextNode(' Dude');
//append these nodes to the DOM
document.querySelector('p').appendChild(elementNode);
document.querySelector('strong').appendChild(textNode);
//log's <p>Hi<strong> Dude</strong></p>
console.log(document.body.innerHTML);
</script>
</body>
</html>
When it becomes necessary to control the location of insertion beyond
appending nodes to the end of a child list of nodes we can use
insertBefore(). In the code below I am inserting the
<li> element before the first child node of the
<ul> element.
<!DOCTYPE html>
<html lang="en">
<body>
<ul>
<li>2</li>
<li>3</li>
</ul>
<script>
//create a text node and li element node and append the text to the li
var text1 = document.createTextNode('1');
var li = document.createElement('li');
li.appendChild(text1);
//select the ul in the document
var ul = document.querySelector('ul');
/*
add the li element we created above to the DOM, notice I call on <ul> and pass reference to <li>2</li> using ul.firstChild
*/
ul.insertBefore(li,ul.firstChild);
console.log(document.body.innerHTML);
/*logs
<ul>
<li>1</li>
<li>2</li>
<li>3</li>
</ul>
*/
</script>
</body>
</html>
The insertBefore() requires two parameters, the node to be
inserted and the reference node in the document you would like the node
inserted before.
Notes
If you do not pass the insertBefore() method a second
parameter then it functions just like appendChild().
We have
more methods
(e.g. prepend(), append(), before(),
after()) to look forward too in DOM 4.
1.11 Removing and replacing nodes using removeChild() and
replaceChild()
Removing a node from the DOM is a bit of a multi-step process. First you
have to select the node you want to remove. Then you need to gain access
to its parent element typically using the parentNode property.
Its on the parent node that you invoke the removeChild() method
passing it the reference to the node to be removed. Below I demonstrate
its use on an element node and text node.
<!DOCTYPE html>
<html lang="en">
<body>
<div id="A">Hi</div>
<div id="B">Dude</div>
<script>
//remove element node
var divA = document.getElementById('A');
divA.parentNode.removeChild(divA);
//remove text node
var divB = document.getElementById('B').firstChild;
divB.parentNode.removeChild(divB);
//log the new DOM updates, which should only show the remaining empty div#B
console.log(document.body.innerHTML);
</script>
</body>
</html>
Replacing an element or text node is not unlike removing one. In the
code below I use the same html structure used in the previous code
example except this time I use replaceChild() to update the
nodes instead of removing them.
<!DOCTYPE html>
<html lang="en">
<body>
<div id="A">Hi</div>
<div id="B">Dude</div>
<script>
//replace element node
var divA = document.getElementById('A');
var newSpan = document.createElement('span');
newSpan.textContent = 'Howdy';
divA.parentNode.replaceChild(newSpan,divA);
//replace text node
var divB = document.getElementById('B').firstChild;
var newText = document.createTextNode('buddy');
divB.parentNode.replaceChild(newText, divB);
//log the new DOM updates,
console.log(document.body.innerHTML);
</script>
</body>
</html>
Notes
Depending upon what you are removing or replacing simply providing the
innerHTML, outerHTML, and
textContent properties with an empty string might be easier
and faster.
Careful memory leaks in brwoser might get you however.
Both replaceChild() and removeChild() return the
replaced or remove node. Basically its not gone just because you
replace it or remove. All this does is takes it out of the current
live document. You still have a reference to it in memory.
We have
more methods
(e.g.replace(), remove()) to look forward too in DOM
4.
1.12 Cloning nodes using cloneNode()
Using the cloneNode() method its possible to duplicate a single
node or a node and all its children nodes.
In the code below I clone only the <ul> (i.e.
HTMLUListElement) which once cloned can be treated like any
node reference.
<!DOCTYPE html>
<html lang="en">
<body>
<ul>
<li>Hi</li>
<li>there</li>
</ul>
<script>
var cloneUL = document.querySelector('ul').cloneNode();
console.log(cloneUL.constructor); //logs HTMLUListElement()
console.log(cloneUL.innerHTML); //logs (an empty string) as only the ul was cloned
</script>
</body>
</html>
To clone a node and all of its children nodes you pass the
cloneNode() method a parameter of of true. Below I use
the cloneNode() method again but this time we clone all of the
child nodes as well.
When cloning an Element node all attributes and values are
also cloned. In fact, only attributes are copied! Everything else you
can add (e.g. event handlers) to a DOM node is lost when cloning.
You might think that cloning a node and its children using
cloneNode(true) would return a NodeList but it in
fact does not.
cloneNode() may lead to duplicate element IDs in a document
When selecting groups of nodes from a tree (cover in chaper 3) or
accessing pre-defined sets of nodes, the nodes are either placed in a
NodeList (e.g.
document.querySelectorAll('*')) or
HTMLCollection
(e.g. document.scripts). These array like (i.e. not a real
Array) object collections that have the following
characteristics.
A collection can either be live or static. Meaning that the nodes
contained in the collection are either literally part of the live
document or a snapshot of the live document.
By default nodes are sorted inside of the collection by tree order.
Meaning the order matches the liner path from tree trunk to branches.
The collections have a length property that reflects the
number of elements in the list
1.14 Gettting a list/collection of all immediate child nodes
Using the childNodes property produces an array like list (i.e.
NodeList) of
the immediate child nodes. Below I select the
<ul> element which I then use to create a list of all of
the immediate child nodes contained inside of the <ul>.
<!DOCTYPE html>
<html lang="en">
<body>
<ul>
<li>Hi</li>
<li>there</li>
</ul>
<script>
var ulElementChildNodes = document.querySelector('ul').childNodes;
console.log(ulElementChildNodes); //logs an array like list of all nodes inside of the ul/*Call forEach as if its a method of NodeLists so we can loop over the NodeList. Done because NodeLists are array like, but do not directly inherit from Array*/
Array.prototype.forEach.call(ulElementChildNodes,function(item){
console.log(item); //logs each item in the array
});
</script>
</body>
</html>
Notes
The NodeList returned by childNodes only contains
immediate child nodes
Be aware childNodes contains not only Element nodes
but also all other node types (e.g. Text and
Comment nodes)
[].forEach was implemented in ECMAScript 5th edtion
1.15 Convert a NodeList or HTMLCollection to
JavaScript Array
Node lists and html collections are array like but not a true JavaScript
array which inherits array methods. In the code below we programtically
confirm this using isArray().
<!DOCTYPE html>
<html lang="en">
<body>
<a href="#"></a>
<script>
console.log(Array.isArray(document.links)); //returns false, its an HTMLCollection not an Array
console.log(Array.isArray(document.querySelectorAll('a'))); //returns false, its an NodeList not an Array
</script>
</body>
</html>
Notes
Array.isArray was implemented in ECMAScript 5th edtion or ES5
Converting a node list and html collection list to a true JavaScript
array can provide a good deal of advantages. For one it gives us the
ability to create a snapshot of the list that is not tied to the live
DOM considering that NodeList and HTMLCollection are
live
lists. Secondly, converting a list to a JavaScript array gives access to
the methods provided by the Array object (e.g.
forEach, pop, map, reduce etc...).
To convert an array like list to a true JavaScript array pass the
array-like list to call() or apply(), in which the
call() or apply() is calling a method that returns an
un-altered true JavaScript array. In the code below I use the
.slice() method, which doesn't really slice anything I am just
using it to convert the list to a JavaScript Array due to the
fact the slice() returns an array.
In ECMAScript 6th edtion we have Array.from to look forward
to which converts a single argument that is an array-like object or
list (eg. arguments, NodeList,
DOMTokenList (used by classList),
NamedNodeMap (used by attributes property)) into a
new Array() and returns it
1.16 Traversing nodes in the DOM
From a node reference (i.e. document.querySelector('ul')) its
possible to get a different node reference by traversing the DOM using
the following properties:
parentNode
firstChild
lastChild
nextSibling
previousSibling
In the code example below we examine the Node properties
providing DOM traversal functionality.
<!DOCTYPE html>
<html lang="en">
<body><ul><!-- comment -->
<li id="A"></li>
<li id="B"></li>
<!-- comment -->
</ul>
<script>
//cache selection of the ul
var ul = document.querySelector('ul');
//What is the parentNode of the ul?
console.log(ul.parentNode.nodeName); //logs body//What is the first child of the ul?
console.log(ul.firstChild.nodeName); //logs comment//What is the last child of the ul?
console.log(ul.lastChild.nodeName); //logs text not comment, because there is a line break//What is the nextSibling of the first li?
console.log(ul.querySelector('#A').nextSibling.nodeName); //logs text//What is the previousSibling of the last li?
console.log(ul.querySelector('#B').previousSibling.nodeName); //logs text
</script>
</body>
</html>
If you have been around the DOM much then it should be no surprise that
traversing the DOM includes not just traversing element nodes but also
text and comment nodes. I believe the last code example makes this
clear, and this is not exactly ideal. Using the following properties we
can traverse the DOM ignoring text and comment nodes.
firstElementChild
lastElementChild
nextElementChild
previousElementChild
children
Notes
The childElementCount is not mentioned but you should be
aware of its avaliablity for calculating the number of child elements
a node contains.
Examine our code example again using only element traversing methods.
<!DOCTYPE html>
<html lang="en">
<body><ul><!-- comment -->
<li id="A"></li>
<li id="B"></li>
<!-- comment -->
</ul>
<script>
//cache selection of the ul
var ul = document.querySelector('ul');
//What is the first child of the ul?
console.log(ul.firstElementChild.nodeName); //logs li//What is the last child of the ul?
console.log(ul.lastElementChild.nodeName); //logs li//What is the nextSibling of the first li?
console.log(ul.querySelector('#A').nextElementSibling.nodeName); //logs li//What is the previousSibling of the last li?
console.log(ul.querySelector('#B').previousElementSibling.nodeName); //logs li//What are the element only child nodes of the ul?
console.log(ul.children); //HTMLCollection, all child nodes including text nodes
</script>
</body>
</html>
1.17 Verify a node position in the DOM tree with
contains() & compareDocumentPosition()
Its possible to know if a node is contained inside of another node by
using the contains()Node method. In the code below I
ask if <body> is contained inside of
<html lang="en">.
If you need more robust information about the position of a node in the
DOM tree in regards to the nodes around it you can use the
compareDocumentPosition()Node method. Basically this
method gives you the ability to request information about a selected
node relative to the node passed in. The information that you get back
is a number that corresponds to the following information.
number code returned from compareDocumentPosition():
number code info:
0
Elements are identical.
1
DOCUMENT_POSITION_DISCONNECTED
Set when selected node and passed in node are not in the same
document.
2
DOCUMENT_POSITION_PRECEDING
Set when passed in node is preceding selected node.
3
DOCUMENT_POSITION_FOLLOWING
Set when passed in node is following selected node.
8
DOCUMENT_POSITION_CONTAINS
Set when passed in node is an ancestor of selected node.
16, 10
DOCUMENT_POSITION_CONTAINED_BY (16, 10 in hexadecimal)
Set when passed in node is a descendant of selected node.
Notes
contains() will return true if the node selected and
node passed in are identical.
compareDocumentPosition() can be rather confusing because its
possible for a node to have more than one type of relationship with
another node. For example when a node both contains (16) and precedes
(4) the returned value from compareDocumentPosition() will be
20.
The following string attributes are
equal: nodeName, localName, namespaceURI, prefix, nodeValue.
That is: they are both null, or they have the same length and are
character for character identical.
The attributesNamedNodeMaps are
equal. That is: they are both null, or they have the
same length and for each node that exists in one map there is a node
that exists in the other map and is equal, although not necessarily at
the same index.
The childNodesNodeLists are equal.
That is: they are both null, or they have the same
length and contain equal nodes at the same index. Note that
normalization can affect equality; to avoid this, nodes should be
normalized before being compared.
Calling the .isEqualNode() method on a node in the DOM will ask
if that node is equal to the node that you pass it as a parameter. Below
I exhibt a case of an two equal nodes and two non-identical nodes.
<!DOCTYPE html>
<html lang="en">
<body>
<input type="text">
<input type="text">
<textarea>foo</textarea>
<textarea>bar</textarea>
<script>
//logs true, because they are exactly idential
var input = document.querySelectorAll('input');
console.log(input[0].isEqualNode(input[1]));
//logs false, because the child text node is not the same
var textarea = document.querySelectorAll('textarea');
console.log(textarea[0].isEqualNode(textarea[1]));
</script>
</body>
</html>
Notes
If you don't care about two nodes being exactly equal but instead want
to know if two node references refer to the same node you can simply
check it using the === opertor (i.e.
document.body === document.body). This will tell us if they
are identical but no equal.
Chapter 2 - Document Nodes
2.1documentnode overview
The HTMLDocument constructor (which inherits from
document) when instantiated represents specifically a
DOCUMENT_NODE (i.e. window.document) in the DOM. To
verify this we can simply ask which constructor was used in the creation
of the document node object.
<!DOCTYPE html>
<html lang="en">
<body>
<script>
console.log(window.document.constructor); //logs function HTMLDocument() { [native code] }
console.log(window.document.nodeType); //logs 9, which is a numeric key mapping to DOCUMENT_NODE
</script>
</body>
</html>
The code above concludes that the HTMLDocument constructor
function constructs the window.document node object and that
this node is a DOCUMENT_NODE object.
Notes
Both Document and HTMLDocument constructors are
typically instantiated by the browser when you load an HTML document.
However, using
document.implementation.createHTMLDocument() its possible to
create your own HTML document outside of the one currently loaded into
the browser. In addtion to createHTMLDocument() its also
possible to create a document object which has yet to be setup as an
HTML document using createDocument(). Typically the use of
theses methods are associated with programatically providing an HTML
document to an iframe.
2.2 HTMLDocument properties and methods (including inherited)
To get accurate information pertaining to the available properties and
methods on an HTMLDocument node its best to ignore the
specification and to ask the browser what is available. Examine the
arrays created in the code below detailing the properties and methods
available from an HTMLDocument node (a.k.a.
window.document) object.
<!DOCTYPE html>
<html lang="en">
<body>
<script>
//document own properties
console.log(Object.keys(document).sort());
//document own properties & inherited properties
var documentPropertiesIncludeInherited = [];
for(var p in document){
documentPropertiesIncludeInherited.push(p);
}
console.log(documentPropertiesIncludeInherited.sort());
//documment inherited properties only
var documentPropertiesOnlyInherited = [];
for(var p in document){
if(
!document.hasOwnProperty(p)){documentPropertiesOnlyInherited.push(p);
}
}
console.log(documentPropertiesOnlyInherited.sort());
</script>
</body>
</html>
The available properties are many even if the inherited properties were
not considered. Below I've hand pick a list of noteworthy properties and
methods for the context of this chapter.
doctype
documentElement
implementation.*
activeElement
body
head
title
lastModified
referrer
URL
defaultview
compatMode
ownerDocument
hasFocus()
Notes
The HTMLDocument node object is used to access (typically
inherit) a great deal of the methods and properties available for
working with the DOM (i.e. document.querySelectorAll()). You
will be seeing many of these properties not discussed in this chapter
discussed in the appropriate chapter's following this chapter.
2.3 Getting general HTML document information (title, url, referrer,
lastModified, compatMode)
The document object provides access to some general information
about the HTML document/DOM being loaded. In the code below I use the
document.title, document.URL,
document.referrer, document.lastModified, and
document.compatMode properties to gain some general information
about the document. Based on the property name the returned
values should be obvious.
Document nodes can contain one DocumentType node
object and one Element node object. This should not be a
surprise since HTML documents typically contain only one doctype (e.g.
<!DOCTYPE html>) and one element (e.g.
<html lang="en">). Thus if you ask for the
children (e.g. document.childNodes) of the
Document object you will get an array containing at the very
least the documents doctype/DTD and
<html lang="en"> element. The code below
showcases that window.document is a type of node object (i.e
Document) with child nodes.
<!DOCTYPE html>
<html lang="en">
<body>
<script>
//This is the doctype/DTD
console.log(document.childNodes[0].nodeType); //logs 10, which is a numeric key mapping to DOCUMENT_TYPE_NODE//This is the <html> element
console.log(document.childNodes[1].nodeType); //logs 1, which is a numeric key mapping to ELEMENT_TYPE_NODE
</script>
</body>
</html>
Notes
Don't confuse the window.document object created from
HTMLDocument constructor with the Document object.
Just remember window.document is the starting point for the
DOM interface. That is why document.childNodes contains child
nodes.
If a comment node (not discussed in this book) is made outside of the
<html lang="en"> element then it will become
a child node of the window.document. However having comment
nodes outside of the <html> element can cause some buggy results
in IE and also is a violation of the DOM specification.
2.5 document provides shortcuts to <!DOCTYPE>,
<html lang="en">, <head>, and
<body>
Using the properties listed below we can get a shortcut reference to the
following nodes:
document.doctype refers to <!DOCTYPE>
document.documentElement refers to
<html lang="en">
The doctype or DTD is a nodeType of 10 or
DOCUMENT_TYPE_NODE and should not be confused with the
DOCUMENT_NODE (aka window.document constructed from
HTMLDocument()). The doctype is constructed from the
DocumentType() constructor.
In Safari, Chrome, and Opera the document.doctype does not
appear in the document.childNodes list.
2.6 Detecting DOM specifications/features using
document.implementation.hasFeature()
Its possible using document.implementation.hasFeature() to ask
(boolean) the current document what feature and level the browser has
implemented/supports. For example we can ask if the browser has
implemented the core DOM level 3 specification by passing the name of
the feature and the version to the hasFeature() method. In the
code below I ask if the browser has implemented the Core 2.0 & 3.0
specification.
The following table defines the features (spec calls these modules) and versions that you can pass the hasFeature() method.
Feature
Supported Versions
Core
1.0, 2.0, 3.0
XML
1.0, 2.0, 3.0
HTML
1.0, 2.0
Views
2.0
StyleSheets
2.0
CSS
2.0
CSS2
2.0
Events
2.0, 3.0
UIEvents
2.0, 3.0
MouseEvents
2.0, 3.0
MutationEvents
2.0, 3.0
HTMLEvents
2.0
Range
2.0
Traversal
2.0
LS (Loading and saving between files and DOM trees synchronously)
3.0
LS-Asnc (Loading and saving between files and DOM trees
asynchronously)
3.0
Validation
3.0
Notes
Don't trust hasFeature() alone you should also use
capability detection
in addition to hasFeature().
Using the isSupported method implementation information can
be gathered for a specific/selected node only (i.e.
element.isSupported(feature,version).
You can determince online what a user agent supports by visiting
http://www.w3.org/2003/02/06-dom-support.html. Here you will find a table indicating what the browser loading the
url claims to implement.
2.7 Get a reference to the focus/active node in the document
Using the document.activeElement we can quickly get a reference
to the node in the document that is focused/active. In the code below,
on page load, I am setting the focus of the document to the
<textarea> node and then gaining a reference to that node
using the activeElement property.
<!DOCTYPE html>
<html lang="en">
<body>
<textarea></textarea>
<script>
//set focus to <textarea>
document.querySelector('textarea').focus();
//get reference to element that is focused/active in the document
console.log(document.activeElement); //logs <textarea>
</script>
</body>
</html>
Notes
The focused/active element returns elements that have the ability to
be focused. If you visit a web page in a browser and start hitting the
tab key you will see focus shifting from element to element in that
page that can get focused. Don't confuse the selection of nodes
(highlight sections of the HTML page with mouse) with elements that
get focus for the purpose of inputting something with keystrokes,
spacebar, or mouse.
2.8 Determing if the document or any node inside of the
document has focus
Using the document.hasFocus() method its possible to know if the user
currently is focused on the window that has the HTML document loaded. In
the code below you see that if we execute the code and then focus
another window, tabe, or application all together the
getFocus() will return false.
<!DOCTYPE html>
<html lang="en">
<body>
<script>
//If you keep focus on the window/tab that has the document loaded its true. If not it's false.
setTimeout(function(){console.log(document.hasFocus())},5000);
</script>
</body>
</html>
2.9 document.defaultview is a shortcut to the head/global
object
You should be aware that the defaultView property is a shortcut
to the JavaScript head object or what some refer to as the global
object. The head object in a web browser is the window object
and defaultView will point to this object in a JavaScript
browser enviroment. The code below demonstrates the value of
defaultView in a browser.
<!DOCTYPE html>
<html lang="en">
<body>
<script>
console.log(document.defaultView) //reference, head JS object. Would be window object in a browser.
</script>
</body>
</html>
If you are dealing with a DOM that is headless or an JavaScript
enviroment that is not running in a web browser (i.e.
node.js) this property can get you
access to the head object scope.
2.9 Getting a reference to the Document from an
element using ownerDocument
The ownerDocument property when called on a node returns a
reference to the Document the node is contained within. In the
code below I get a reference to the Document of the
<body> in the HTML document and the
Document node for the <body> element contained
inside of the iframe.
live code: N/A
<!DOCTYPE html>
<html lang="en">
<body>
<iframe src="http://someFileServedFromServerOnSameDomain.html"></iframe>
<script>
//get the window.document that the <body> is contained within
console.log(document.body.ownerElement);
//get the window.document the <body> inside of the iframe is contained within
console.log(window.frames[0].document.body.ownerElement);
</script>
</body>
</html>
If ownerDocument is called on the Document node the
value returned is null.
Chapter 3 - Element Nodes
3.1 HTML*Element object overview
Elements in an html document all have a unique nature and as such they
all have a unique
JavaScript constructor
that instantiates the element as a node object in a DOM tree. For
example an <a> element is created as a DOM node from the
HTMLAnchorElement() constructor. Below we verify that an anchor
element is created from HTMLAnchorElement().
<!DOCTYPE html>
<html lang="en">
<body>
<a></a>
<script>
// grab <a> element node from DOM and ask for the name of the constructor that constructed it
console.log(document.querySelector('a').constructor);
//logs function HTMLAnchorElement() { [native code] }
</script>
</body>
</html>
The point I am trying to express in the previous code example is that
each element in the DOM is constructed from a unique JavaScript
intefaces/constructor. The list below (not a
complete list) should give you a good sense of the interfaces/constructors used to
create HTML elements.
HTMLHtmlElement
HTMLHeadElement
HTMLLinkElement
HTMLTitleElement
HTMLMetaElement
HTMLBaseElement
HTMLIsIndexElement
HTMLStyleElement
HTMLBodyElement
HTMLFormElement
HTMLSelectElement
HTMLOptGroupElement
HTMLOptionElement
HTMLInputElement
HTMLTextAreaElement
HTMLButtonElement
HTMLLabelElement
HTMLFieldSetElement
HTMLLegendElement
HTMLUListElement
HTMLOListElement
HTMLDListElement
HTMLDirectoryElement
HTMLMenuElement
HTMLLIElement
HTMLDivElement
HTMLParagraphElement
HTMLHeadingElement
HTMLQuoteElement
HTMLPreElement
HTMLBRElement
HTMLBaseFontElement
HTMLFontElement
HTMLHRElement
HTMLModElement
HTMLAnchorElement
HTMLImageElement
HTMLObjectElement
HTMLParamElement
HTMLAppletElement
HTMLMapElement
HTMLAreaElement
HTMLScriptElement
HTMLTableElement
HTMLTableCaptionElement
HTMLTableColElement
HTMLTableSectionElement
HTMLTableRowElement
HTMLTableCellElement
HTMLFrameSetElement
HTMLFrameElement
HTMLIFrameElement
Keep in mind each HTML*Element above inherits properties and
methods from HTMLElement, Element, Node, and
Object.
3.2 HTML*Element object properties and methods (including
inherited)
To get accurate information pertaining to the available properties and
methods on an HTML*Element node
its best to ignore the specification and to ask the browser what is
available. Examine the arrays created in the code below detailing the
properties and methods available from
HTMLelement nodes.
<!DOCTYPE html>
<html lang="en">
<body>
<a href="#">Hi</a>
<script>
var anchor = document.querySelector('a');
//element own properties
console.log(Object.keys(anchor).sort());
//element own properties & inherited properties
var documentPropertiesIncludeInherited = [];
for(var p in document){
documentPropertiesIncludeInherited.push(p);
}
console.log(documentPropertiesIncludeInherited.sort());
//element inherited properties only
var documentPropertiesOnlyInherited = [];
for(var p in document){
if(!document.hasOwnProperty(p)){
documentPropertiesOnlyInherited.push(p);
}
}
console.log(documentPropertiesOnlyInherited.sort());
</script>
</body>
</html>
The available properties are many even if the inherited properties were
not considered. Below I've hand pick a list of note worthy properties
and methods (inherited as well) for the context of this chapter.
createElement()
tagName
children
getAttribute()
setAttribute()
hasAttribute()
removeAttribute()
classList()
dataset
attributes
For a complete list check out the MDN documentation which covers the
general properties and methods
available to most HTML elements.
3.3 Creating Elements
Element nodes are instantiated for us when a browser interputs
an HTML document and a corresponding DOM is built based on the contents
of the document. After this fact, its also possible to programaticlly
create Element nodes using createElement(). In the
code below I create a <textarea> element node and then
inject that node into the live DOM tree.
<!DOCTYPE html>
<html lang="en">
<body>
<script>
var elementNode = document.createElement('textarea'); //HTMLTextAreaElement() constructs <textarea>
document.body.appendChild(elementNode);
console.log(document.querySelector('textarea')); //verify it's now in the DOM
</script>
</body>
</html>
The value passed to the createElement() method is a string that
specifices the type of element (aka
tagName) to be created.
Notes
This value passed to createElement is changed to a lower-case string
before the element is created.
3.4 Get the tag name of an element
Using the tagName property we can access the name of an
element. The tagName property returns the same value that using
nodeName would return. Both return the value in uppercase
regardless of the case in the source HTML document.
Below we get the name of an <a> element in the DOM.
<!DOCTYPE html>
<html lang="en">
<body>
<a href="#">Hi</a>
<script>
console.log(document.querySelector('a').tagName); //logs A//the nodeName property returns the same value
console.log(document.querySelector('a').nodeName); //logs A
</script>
</body>
</html>
3.5 Getting a list/collection of element attributes and values
Using the attributes property (inherited by element nodes from
Node) we can get a collection of the
Attrnodes that an element currently has defined. The list returned is a
NameNodeMap. Below I loop over the attributes collection exposing each
Attr node object contained in the collection.
The array returned from accessing the attributes property should be
consider live. Meaning that its contents can be changed at anytime.
The array that is returned inherits from the
NameNodeMap which provides methods to operate on the array
such as getNamtedItem(), setNamedItem(), and
removeNamedItem(). Operating on attributes with
these methods should be secondary to using getAttribute(),
setAttribute(), hasAttribute(),
removeAttribute(). Its this authors opinion that dealing with
Attr
nodes is messy. The only merit in using the attributes is
found only in its funcitonaly for returning a list of live attributes.
The attributes property is an array like collection and has a
read only length property.
Boolean attributres (e.g.
<option selected>foo</option>) show up in the
attributes list but of course have no value unless you
provide one (e.g.
<option selected="selected">foo</option>).
3.6 Getting, Setting, & Removing an element's attribute value
The most consistent way to get, set, or remove an elements
attribute
value is to use the getAttribute(), setAttribute(), and
removeAttribute() method. In the code below I demonstrate each
of these methods for managing element attributes.
Use removeAttribute() instead of setting the attribute value
to null or '' using setAttribute()
Some element attributes are available from element nodes as object
properties (i.e. document.body.id or
document.body.className). This author recommends avoiding
these properties and using the remove, set, and get attribute methods.
3.7 Verifying an element has a specific attribute
The best way to determine (i.e. boolean) if an element has an attribute
is to use the hasAttribute() method. Below I verify if
the <a> has a href, title,
style, data-foo, class, and
foo attribute.
<!DOCTYPE html>
<html lang="en">
<body>
<a href='#' title="title" data-foo="dataFoo" style="margin:0;" class="yes" goo></a>
<script>
var atts = document.querySelector('a');
console.log(
atts.hasAttribute('href'),
atts.hasAttribute('title'),
atts.hasAttribute('style'),
atts.hasAttribute('data-foo'),
atts.hasAttribute('class'),
atts.hasAttribute('goo') //Notice this is true regardless if a value is defined
)
</script>
</body>
</html>
This method will return true if the element contains the
attribute even if the attribute has no value. For example using
hasAttribute() we can get a boolean response for
boolean attributes. In the code example below we check to see if a checkbox is checked.
Using the classList property available on element nodes we can
access a list (i.e.
DOMTokenList) of class attribute values that is much easier to work with than a
space-delimited string value returned from the
className property. In the code below I contrast the use of
classList with className.
<!DOCTYPE html>
<html lang="en">
<body>
<div class="big brown bear"></div>
<script>
var elm = document.querySelector('div');
console.log(elm.classList); //big brown bear {0="big", 1="brown", 2="bear", length=3, ...}
console.log(elm.className); //logs 'big brown bear'
</script>
</body>
</html>
Notes
Given the classList is an array like collection it has a read
only length property.
classList is read-only but can be modifyied using the
add(), remove(), contains(), and
toggle() methods
IE9 does not support classList. Support will land in
IE10. Severalpolyfills are avaliable.
3.9 Adding & removing sub-values to a class attribute
Using the classList.add() and
classList.remove() methods its extremely simple to edit the
value of a class attribute. In the code below I demonstrated adding and
removing class values.
<!DOCTYPE html>
<html lang="en">
<body>
<div class="dog"></div>
<script>
var elm = document.querySelector('div');
elm.classList.add('cat');
elm.classList.remove('dog');
console.log(elm.className); //'cat'
</script>
</body>
</html>
3.10 Toggling a class attribute value
Using the classList.toggle() method we can toggle a sub-value
of the class attribute. This allows us to add a value if its missing or
remove a value if its already added. In the code below I toggle the
'visible' value and the 'grow' value. Which
essentially means I remove 'visible' and add 'grow' to
the class attribute value.
<!DOCTYPE html>
<html lang="en">
<body>
<div class="visible"></div>
<script>
var elm = document.querySelector('div');
elm.classList.toggle('visible');
elm.classList.toggle('grow');
console.log(elm.className); //'grow'
</script>
</body>
</html>
3.11 Determining if a class attribute value contains a specific value
Using the classList.contains() method its possible to determine
(boolean) if a class attribute value contains a specific sub-value. In
the code below we test weather the <div> class attribute
contains a sub-value of brown.
<!DOCTYPE html>
<html lang="en">
<body>
<div class="big brown bear"></div>
<script>
var elm = document.querySelector('div');
console.log(elm.classList.contains('brown')); //logs true
</script>
</body>
</html>
3.12 Getting & Setting data-* attributes
The dataset property of a element node provides an object
containing all of the attributes of an element that starts with data-*.
Because its a simply a JavaScript object we can manipulate
dataset and have the element in the DOM reflect those changes
<!DOCTYPE html>
<html lang="en">
<body>
<div data-foo-foo="foo" data-bar-bar="bar"></div>
<script>
var elm = document.querySelector('div');
//get
console.log(elm.dataset.fooFoo); //logs 'foo'
console.log(elm.dataset.barBar); //logs 'bar'//setelm.dataset.gooGoo = 'goo';
console.log(elm.dataset); //logs DOMStringMap {fooFoo="foo", barBar="bar", gooGoo="goo"}//what the element looks like in the DOM
console.log(elm); //logs <div data-foo-foo="foo" data-bar-bar="bar" data-goo-goo="goo">
</script>
</body>
</html>
Notes
dataset contains camel case versions of data attributes.
Meaning data-foo-foo will be listed as the property
fooFoo in the dataset DOMStringMap object. The-
is replaced by camel casing.
Removing a data-* attribute from the DOM is as simple using the
delete operator on a property of the datset (e.g.
delete dataset.fooFoo)
dataset is not supported in IE9. A
polyfill
is avaliable. However, you can always just use
getAttribute('data-foo'), removeAttribute('data-foo'),
setAttribute('data-foo'), hasAttribute('data-foo').
Chapter 4 - Element Node Selecting
4.1 Selecting a specific element node
The most common methods for getting a reference to a single element node
are:
querySelector()
getElementById()
In the code below I leverage both of these methods to select an element
node from the HTML document.
The getElementById() method is pretty simple compared to the
more robust querySelector() method. The
querySelector() method permits a parameter in the form of a
CSS selector syntax. Basically you can pass this method a CSS 3 selector (e.g.
'#score>tbody>tr>td:nth-of-type(2)') which it will use
to select a single element in the DOM.
Notes
querySelector() will return the first node element found in
the document based on the selector. For example, in the code example
above we pass a selector that would select all the li's in CSS, but
only the first one is returned.
querySelector() is also defined on element nodes. This allows
for the method to limit (allows for context querying) its results to a
specific vein of the DOM tree
4.2 Selecting/creating a list (aka NodeList) of element nodes
The most common methods for selecting/creating a list of nodes in an
HTML document are:
querySelectorAll()
getElementsByTagName()
getElementsByClassName()
Below we use all three of these methods to create a list of the
<li> elements in the document.
<!DOCTYPE html>
<html lang="en">
<body>
<ul>
<li class="liClass">Hello</li>
<li class="liClass">big</li>
<li class="liClass">bad</li>
<li class="liClass">world</li>
</ul>
<script>
//all of the methods below create/select the same list of <li> elements from the DOM
console.log(document.querySelectorAll('li'));
console.log(document.getElementsByTagName('li'));
console.log(document.getElementsByClassName('liClass'));
</script>
</body>
</html>
If its not clear the methods used in the code example above do not
select a specific element, but instead creates a list (aka
NodeLists) of elements that you can select from.
Notes
NodeLists created from getElementsByTagName() and
getElementsByClassName() are considered live are will always
reflect the state of the document even if the document is updated
after the list is created/selected.
The querySelectorAll() method does not return a live list of
elements. Meaning that the list created from
querySelectorAll() is a snap shot of the document at the time
it was created and is not reflective of the document as it changes.
The list is static not live.
querySelectorAll(), getElementsByTagName(), and
getElementsByClassName are also defined on element nodes.
This allows for the method to limit its results to specific vein(s) of
the DOM tree (e.g.
document.getElementById('header').getElementsByClassName('a')).
I did not mention the getElementsByName() method as it not
commonly leverage over other solutions but you should be aware of its
existence for selecting form, img, frame, embed, and object elements
from a document that all have the same name attribute value.
Passing either querySelectorAll() or
getElementsByTagName() the string '*', which
generally means all, will return a list of all elements in the
document.
Keep in mind that childNodes will also return a
NodeList just like querySelectorAll(),
getElementsByTagName(), and getElementsByClassName
The NodeLists are array like (but does not inherit array
methods) lists/collections and have a read only
length property
4.3 Selecting all immediate child element nodes
Using the children property from an element node we can get a
list (aka
HTMLCollection) of all the immediate children nodes that are element nodes. In the
code below I use children to create a selection/list of all of
the <li>'s contained wiithin the <ul>.
<!DOCTYPE html>
<html lang="en">
<body>
<ul>
<li><strong>Hi</strong></li>
<li>there</li>
</ul>
<script>
var ulElement = document.querySelector('ul').children;
//logs a list/array of all immediate child element nodes
console.log(ulElement); //logs [<li>, <li>]
</script>
</body>
</html>
Notice that using children only gives us the immediate element
nodes excluding any nodes (e.g. text nodes) that are not elements. If
the element has no children then children will return an empty
array-like-list.
Notes
HTMLCollection's contain elements in document order, that is
they are placed in the array in the order the elements appear in the
DOM
HTMLCollection's are live, which means any change to the
document will be reflected dynamically in the collection
4.4 Contextual element selecting
The methods querySelector(), querySelectorAll(),
getElementsByTagName(), and
getElementsByClassName typically accessed from the
document object are also defined on element nodes. This allows
for these methods to limit its results to specific vein(s) of the DOM
tree. Or said another, you can select a specific context in which you
would like the methods to search for element nodes by invoking these
methods on element node objects.
<!DOCTYPE html>
<html lang="en">
<body>
<div> <ul> <li class="liClass">Hello</li> <li class="liClass">big</li> <li class="liClass">bad</li> <li class="liClass">world</li> </ul> </div>
<ul> <li class="liClass">Hello</li> </ul>
<script>
//select a div as the context to run the selecting methods only on the contents of the divvar div = document.querySelector('div');
console.log(div.querySelector('ul'));
console.log(div.querySelectorAll('li'));
console.log(div.getElementsByTagName('li'));
console.log(div.getElementsByClassName('liClass'));
</script>
</body>
</html>
These methods not only operate on the live dom but programatic DOM
structures that are created in code as well.
<!DOCTYPE html>
<html lang="en">
<body>
<script>
//create DOM structure
var divElm = document.createElement('div');
var ulElm = document.createElement('ul');
var liElm = document.createElement('li');
liElm.setAttribute('class','liClass');
ulElm.appendChild(liElm);
divElm.appendChild(ulElm);
//use selecting methods on DOM structure
console.log(divElm.querySelector('ul'));
console.log(divElm.querySelectorAll('li'));
console.log(divElm.getElementsByTagName('li'));
console.log(divElm.getElementsByClassName('liClass'));
</body>
</html>
4.5 Pre-configured selections/lists of element nodes
You should be aware that there are some legacy, pre-configured
arrays-like-lists, containing element nodes from an HTML document. Below
I list a couple of these (not the complete list) that might be handy to
be aware of.
document.all - all elements in HTML document
document.forms - all <form> elements in HTML
document
document.images - all <img> elements in HTML
document
document.links - all <a> elements in HTML
document
document.scripts - all <script> elements in
HTML document
document.styleSheets - all <link> or
<style> objects in HTML document
Notes
These pre-configured arrays are constucted from the
HTMLCollection
interface/object, except document.styleSheets it uses
StyleSheetList
Oddly document.all is constucted from a
HTMLAllCollection
not an HTMLCollection and is not supported in Firefox
4.6 Verify an element will be selected using matchesSelector()
Using the matchesSelector() method we can determine if an
element will match a selector string. For example say we want to
determine if an <li> is the first child element of a
<ul>. In the code example below I select the first
<li> inside of the <ul> and then ask if
that element matches the selector, li:first-child. Because it
in fact does, the matchesSelector() method returns
true.
<!DOCTYPE html>
<html lang="en">
<body>
<ul>
<li>Hello</li>
<li>world</li>
</ul>
<script>
//fails in modern browser must use browser prefix moz, webkit, o, and ms
console.log(document.querySelector('li').matchesSelector('li:first-child')); //logs false
//prefix moz
//console.log(document.querySelector('li').mozMatchesSelector('li:first-child'));
//prefix webkit
//console.log(document.querySelector('li').webkitMatchesSelector('li:first-child'));
//prefix o
//console.log(document.querySelector('li').oMatchesSelector('li:first-child'));
//prefix ms
//console.log(document.querySelector('li').msMatchesSelector('li:first-child'));
</script>
</body>
</html>
Notes
matchesSelector has not seen much love from the browsers as its usage
is behind browser prefixes mozMatchesSelector(),
webkitMatchesSelector(), oMatchesSelector(),
msMatchesSelector()
In the future matchesSelector() will be renamed to
matches()
Chapter 5 - Element Node Geometry & Scrolling Geometry
5.1 Element node size, offsets, and scrolling overview
DOM nodes are parsed and
painted
into visual shapes when viewing html documents in a web browser. Nodes,
mostly element nodes, have a corresponding visual representation made
viewable/visual by browsers. To inspect and in some cases manipulate the
visual representation and gemometry of nodes programatically a set of
API's exists and are specified in the
CSSOM View Module. A
subset of methods and properties found in this specification provide an
API to determine the geometry (i.e. size & position using offset) of
element nodes as well as hooks for manipulating scrollable nodes and
getting values of scrolled nodes. This chapter breaks down these methods
and properties.
Notes
Most of the properties (excluding scrollLeft &
scrollTop) from the CSSOM View Module specification are read
only and calculated each time they are accessed. In other words, the
values are live
5.2 Getting an elements offsetTop and
offsetLeft values relative to the offsetParent
Using the properties offsetTop and offsetLeft we can
get the offset pixel value of an element node from the
offsetParent. These element node properties give us the
distance in pixels from an elements outside top and left border to the
inside top and left border of the offsetParent. The value of
the offsetParent is determined by searching the nearest
ancestor elements for an element that has a CSS position value not equal
to static. If none are found then the <body> element or
what some refer to as the "document" (as opposed to the
browser viewport) is the offsetParent value. If during the
ancestral search a <td>, <th>, or
<table> element with a CSS position value of static is
found then this becomes the value of offsetParent.
Lets verify that offsetTop and offsetLeft provide the
values one might expect. The properties offsetLeft and
offsetTop in the code below tell us that the
<div> with an id of red is 60px's from
the top and left of the offsetParent (i.e. the
<body> element in this example).
Examine the following image showing what the code visually show in
browser to help aid your understanding of how the
offsetLeft and offsetTop values are deteremined. The
red <div> shown in the image is exactly 60 pixels from
the offsetParent.
Notice I am measuring from the outside border of the red
<div> element to the inside border of the
offsetParent (i.e. <body>).
As previously mentioned If I was to change the blue
<div> in the above code to have a position of absolute
this would alter the value of the offsetParent. In the code
below, absolutely positioning the blue <div> will cause
the values returned from offsetLeft and offsetTop to
report an offset (i.e. 25px's). This is because the offset parent is now
the blue <div> and not the <body> .
The image of the browser view shown below clarifies the new measurements
returned from offsetLeft and offsetTop when the
offsetParent is the blue <div>.
Notes
Many of the browsers break the outside border to inside border
measurement when the offsetParent is the
<body> and the <body> or
<html> element has a visible margin, padding, or border
value.
The offsetParent, offsetTop, and
offsetLeft are extensions to the HTMLelement object.
5.3 Getting an elements top, right, bottom and left border edge offset
relative to the viewport using getBoundingClientRect()
Using the getBoundingClientRect() method we can get the
position of an elements outside border edges as its painted in the
browser viewport relative to the top and left edge of the viewport. This
means the left and right edge are measured from the outside border edge
of an element to the left edge of the viewport. And the top and bottom
edges are measured from the outside border edge of an element to the top
edge of the viewport.
In the code below I create a 50px X 50px <div> with a
10px border and 100px margin. To get the distance in pixels from each
border edge of the <div> I call the
getBoundingClientRect()
method on the <div> which returns an object containing a
top, right, bottom, and
left property.
The image below shows the browser rendered view of the above code with
some added measurement indicators to show exactly how
getBoudingClientRect() is calculated.
The top outside border edge of the <div> element
is 100px from the top edge of the viewport. The right outside
border edge of the element <div> is 170px from the left
edge of the viewport. The bottom outside border edge of the
element <div> is 170px from the top edge of the viewport.
And the left outside border edge of the element
<div> is 100px from the left edge of the viewport.
5.4 Getting an elements size (border + padding + content) in the
viewport
The getBoundingClientRect() returns an object with a top,
right, bottom, and left property/value but also with a height and width
property/value. The height and width properties
indicate the size of the element where the total size is derived by
adding the content of the div, its padding, and borders together.
In the code below I get the size of the <div> element in
the DOM using getBoundingClientRect().
var div = document.querySelector('div').getBoundingClientRect();
console.log(div.height, div.width); //logs '125 125'//because 25px border + 25px padding + 25 content + 25 padding + 25 border = 125
</script> </body>
</html>
The exact same size values can also be found using from the
offsetHeight and offsetWidth properties. In the code
below I leverage these properties to get the same exact height and width
values provided by getBoundingClientRect().
var div = document.querySelector('div');
console.log(div.offsetHeight, div.offsetWidth); //logs '125 125'//because 25px border + 25px padding + 25 content + 25 padding + 25 border = 125
</script> </body>
</html>
5.5 Getting an elements size (padding + content) in the viewport
excluding borders
The clientWidth and clientHeight properties return a
total size of an element by adding together the content of the element
and its padding excluding the border sizes. In the code below I use
these two properties to get the height and width of an element including
padding but excluding borders.
var div = document.querySelector('div');
console.log(div.clientHeight, div.clientWidth); //logs '75 75' because 25px padding + 25 content + 25 padding = 75
</script> </body>
</html>
5.6 Getting topmost element in viewport at a specific point using
elementFromPoint()
Using elementFromPoint() it's possible to get a reference to
the topmost element in an html document at a specific point in the
document. In the code example below I simply ask what is the topmost
element 50 pixels from the top and left of the viewport. Since we have
two <div>'s at that location the topmost (or if there is
no z-index set the last one in document order) div is selected and
returned.
5.7 Getting the size of the element being scrolled using
scrollHeight and scrollWidth
The scrollHeight and scrollWidth properties simply
give you the height and width of the node being scrolled. For example,
open any HTML document that scrolls in a web browser and access these
properties on the <html> (e.g.
document.documentElement.scrollWidth) or <body> (e.g. document.body.scrollWidth)
and you will get the total size of the HTML document being scrolled.
Since we can apply, using CSS (i.e overflow:scroll), to elements lets
look at a simpler code example. In the code below I make a
<div> scroll a <p> element that is
1000px's x 1000px's. Accessing the scrollHeight and
scrollWidth properties on the <div> will tell us
that the element being scroll is 1000px's x 1000px's.
If you need to know the height and width of the node inside a
scrollable area when the node is smaller than the viewport of the
scrollable area don't use scrollHeight and
scrollWidth as this will give you the size of the viewport.
If the node being scrolled is smaller than the scroll area then use
clientHeight and clientWidth to determine the size
of the node contained in the scrollable area.
5.8 Getting & Setting pixels scrolled from the top and left using
scrollTop and scrollLeft
The scrollTop and scrollLeft properties are read-write
properties that return the pixels to the left or top that are not
currently viewable in the scrollable viewport due to scrolling. In the
code below I setup a <div> that scrolls a
<p> element.
I programatically scroll the <div> by setting the
scrollTop and scrollLeft to 750. Then I get the
current value of scrollTop and scrollLeft, which of
course since we just set the value to 750 will return a value of 750.
The 750 reports the number of pixels scroll and indicates 750 px's to
the left and top are not viewable in the viewport. If it helps just
think of these properties as the pixel measurements of the content that
is not shown in the viewport to the left or top.
5.9 Scrolling an element into view using scrollIntoView()
By selecting a node contained inside a node that is scrollable we can
tell the selected node to scroll into view using the
scrollIntoView() method. In the code below I select the fifth
<p> element contained in the scrolling
<div> and call scrollIntoView() on it.
<script> //select <p>5</p> and scroll that element into view, I pass children '4' because its a zero index array-like structure document.querySelector('content').children[4].scrollIntoView(true);
</script> </body>
</html>
By passing the scrollIntoView() method a parameter of
true I am telling the method to scroll to the top of the
element being scrolled too. The true parameter is however not
needed as this is the default action performed by the method. If you
want to scroll align to the bottom of the element pass a parameter of
false to the scrollIntoView() method.
Chapter 6 - Element Node Inline Styles
6.1 Style Attribute (aka element inline CSS properties) Overview
Every HTML element has a style attribute that can be used to inline CSS
properties specific to the element. In the code below I am accessing the
style attribute of a <div> that contains several
inline CSS properties.
Notice in the code above that what is returned from the
style property is a CSSStyleDeclaration object and not
a string. Additionally note that only the elements inline styles (i.e.
excluding the computed styles, computed styles being any styles that
have cascaded from style sheets) are included in the
CSSStyleDeclartion object.
Inline CSS styles are individually represented as a property (i.e.
object property) of the style object avaliabe on element node
objects. This provides the interface for us to get, set, or remove
individual CSS properties on an element by simply setting an objects
property value. In the code below we set, get, and remove styles on a
<div> by manipulating the properties of the
style object.
The property names contained in the style object do not contain the
normal hyphen that is used in CSS property names. The translation is
pretty simple. Remove the hyphen and use camel case. (e.g. font-size =
fontSize or background-image = backgroundImage). In
the case where a css property name is a JavaScript keyword the
javascript css property name is prefixed with "css" (e.g. float =
cssFloat).
Short hand properties are available as properties as well. So you can
not only set margin, but also marginTop.
Remember to include for any css property value that requires a unit of
measure the appropriate unit (e.g.
style.width = '300px';not style.width = '300';).
When a document is rendered in standards mode the unit of measure is
require or it will be ignored. In quirksmode assumptions are made if
not unit of measure is included.
CSS Property
JavaScript Property
background
background
background-attachment
backgroundAttachment
background-color
backgroundColor
background-image
backgroundImage
background-position
backgroundPosition
background-repeat
backgroundRepeat
border
border
border-bottom
borderBottom
border-bottom-color
borderBottomColor
border-bottom-style
borderBottomStyle
border-bottom-width
borderBottomWidth
border-color
borderColor
border-left
borderLeft
border-left-color
borderLeftColor
border-left-style
borderLeftStyle
border-left-width
borderLeftWidth
border-right
borderRight
border-right-color
borderRightColor
border-right-style
borderRightStyle
border-right-width
borderRightWidth
border-style
borderStyle
border-top
borderTop
border-top-color
borderTopColor
border-top-style
borderTopStyle
border-top-width
borderTopWidth
border-width
borderWidth
clear
clear
clip
clip
color
color
cursor
cursor
display
display
filter
filter
font
font
font-family
fontFamily
font-size
fontSize
font-variant
fontVariant
font-weight
fontWeight
height
height
left
left
letter-spacing
letterSpacing
line-height
lineHeight
list-style
listStyle
list-style-image
listStyleImage
list-style-position
listStylePosition
list-style-type
listStyleType
margin
margin
margin-bottom
marginBottom
margin-left
marginLeft
margin-right
marginRight
margin-top
marginTop
overflow
overflow
padding
padding
padding-bottom
paddingBottom
padding-left
paddingLeft
padding-right
paddingRight
padding-top
paddingTop
page-break-after
pageBreakAfter
page-break-before
pageBreakBefore
position
position
float
styleFloat
text-align
textAlign
text-decoration
textDecoration
text-decoration: blink
textDecorationBlink
text-decoration: line-through
textDecorationLineThrough
text-decoration: none
textDecorationNone
text-decoration: overline
textDecorationOverline
text-decoration: underline
textDecorationUnderline
text-indent
textIndent
text-transform
textTransform
top
top
vertical-align
verticalAlign
visibility
visibility
width
width
z-index
zIndex
The style object is a CSSStyleDeclaration object and it
provides not only access to inidividual CSS properties, but also the
setPropertyValue(propertyName),
getPropertyValue(propertyName,value), and
removeProperty() methods used to manipulate individual CSS
properties on a element node. In the code below we set, get, and remove
individual CSS properties on a <div> using these methods.
Take notice that the property name is passed to the
setProperty() and getPropertyValue() method using
the css property name including a hyphen (e.g.
background-color not backgroundColor).
For more detailed information about the setProperty(),
getPropertyValue(), and removeProperty() as well as
additional properties and methods have a look the
documentation
provided by Mozilla.
6.3 Getting, setting, & removing all inline CSS properties
Its possible using the cssText property of the
CSSStyleDeclaration object as well as the
getAttribute() and setAttribute() method to get, set,
and remove the entire (i.e. all inline CSS properties) value of the
style attribute using a JavaScript string. In the code below we get,
set, and remove all inline CSS (as opposed to individually changing CSS
proeprties) on a <div>.
<!DOCTYPE html>
<html lang="en">
<body>
<div></div>
<script>
var div = document.querySelector('div');
var divStyle = div.style;
//set using cssText
divStyle.cssText = 'background-color:red;border:1px solid black;height:100px;width:100px;';
//get using cssText
console.log(divStyle.cssText);
//remove
divStyle.cssText = '';
//exactly that same outcome using setAttribute() and getAttribute()//set using setAttribute
div.setAttribute('style','background-color:red;border:1px solid black;height:100px;width:100px;');
//get using getAttribute
console.log(div.getAttribute('style'));
//remove
div.removeAttribute('style');
</script>
</body>
</html>
Notes
If its not obvious you should note that replacing the
style attribute value with a new string is the fastest way to
make multiple changes to an elements style.
6.4 Getting an elements computed styles (i.e. actual styles including
any from the cascade) using getComputedStyle()
The style property only contains the css that is defined via
the style attribute. To get an elements css from the cascade (i.e.
cascading from inline style sheets, external style sheets, browser style
sheets) as well as its inline styles you can use
getComputedStyle(). This method provides a read-only
CSSStyleDeclaration object similar to style. In the
code example below I demonstrate the reading of cascading styles, not
just element inline styles.
<!DOCTYPE html>
<html lang="en">
<head>
<style>
div{
background-color:red;
border:1px solid black;
height:100px;
width:100px;
}
</style>
</head>
<body>
<div style="background-color:green;border:1px solid purple;"></div>
<script>
var div = document.querySelector('div');
//logs rgb(0, 128, 0) or green, this is an inline element style
console.log(window.getComputedStyle(div).backgroundColor);
//logs 1px solid rgb(128, 0, 128) or 1px solid purple, this is an inline element style
console.log(window.getComputedStyle(div).border);
//logs 100px, note this is not an inline element style
console.log(window.getComputedStyle(div).height);
//logs 100px, note this is not an inline element style
console.log(window.getComputedStyle(div).width);
</script>
</body>
</html>
Make sure you note that getComputedStyle() method honors the
CSS specificity hierarchy. For example in the code just shown the backgroundColor of
the <div> is reported as green not red because inline
styles are at the top of the specificity hierarchy thus its the inline
backgroundColor value that is applied to the element by the
browser and consider its final computed style.
Notes
No values can by set on a CSSStyleDeclaration object returned
from getComputedStyles() its read only.
The getComputedStyles() method returns color values in the
rgb(#,#,#) format regardless of how they were originally
authored.
Shorthand
properties are not computed for the
CSSStyleDeclaration object you will have to use non-shorthand
property names for property access (e.g. marginTop not margin).
6.5 Apply & remove css properties on an element using
class & id attributes
Style rules defined in a inline style sheet or external style sheet can
be added or removed from an element using the class and
id attribute. This is a the most common pattern for
manipulating element styles. In the code below, leveraging
setAttribute() and classList.add(), inline style rules
are applied to a <div> by setting the class and
id attribute value. Using removeAttribute() and
classList.remove() these CSS rules can be removed as well.
Text in an HTML document is represented by instances of the
Text() constructor function, which produces text nodes. When an
HTML document is parsed the text mixed in among the elements of an HTML
page are converted to text nodes.
<!DOCTYPE html>
<html lang="en">
<body>
<p>hi</p>
<script>
//select 'hi' text node
var textHi = document.querySelector('p').firstChild
console.log(textHi.constructor); //logs Text()//logs Text {textContent="hi", length=2, wholeText="hi", ...}
console.log(textHi);
</script>
</body>
</html>
The code above concludes that the Text() constructor function
constructs the text node but keep in mind that
Text inherits from
CharacterData, Node, and Object.
7.2 Text object & properties
To get accurate information pertaining to the available properties and
methods on an Text node its best to ignore the specification
and to ask the browser what is available. Examine the arrays created in
the code below detailing the properties and methods available from a
text node.
<!DOCTYPE html>
<html lang="en">
<body>
<p>hi</p>
<script>
var text = document.querySelector('p').firstChild;
//text own properties
console.log(Object.keys(text).sort());
//text own properties & inherited properties
var textPropertiesIncludeInherited = [];
for(var p in text){
textPropertiesIncludeInherited.push(p);
}
console.log(textPropertiesIncludeInherited.sort());
//text inherited properties only
var textPropertiesOnlyInherited = [];
for(var p in text){
if(!text.hasOwnProperty(p)){
textPropertiesOnlyInherited.push(p);
}
}
console.log(textPropertiesOnlyInherited.sort());
</script>
</body>
</html>
The available properties are many even if the inherited properties were
not considered. Below I've hand pick a list of note worthy properties
and methods for the context of this chapter.
textContent
splitText()
appendData()
deleteData()
insertData()
replaceData()
subStringData()
normalize()
data
document.createTextNode() (not a property or inherited
property of text nodes but discussed in this chapter)
7.3 White space creates Text nodes
When a DOM is contstructed either by the browser or by programmatic
means text nodes are created from white space as well as from text
characters. After all, whitespace is a character. In the code below the
second paragraph, conaining an empty space, has a child
Text node while the first paragraph does not.
Don't forget that white space and text characters in the DOM are
typically represented by a text node. This of course means that carriage
returns are considered text nodes. In the code below we log a carriage
return highlighting the fact that this type of character is in fact a
text node.
<!DOCTYPE html>
<html lang="en">
<body>
<p id="p1"></p>//yes there is a carriage return text node before this comment, even this comment is a node
<p id="p2"></p>
<script>
console.log(document.querySelector('#p1').nextSibling) //logs Text
</script>
</body>
</html>
The reality is if you can input the character or whitespace into an html
document using a keyboard then it can potentially be interputed as a
text node. If you think about it, unless you minimze/compress the html
document the average html page contains a great deal of whitespace and
carriage return text nodes.
7.4 Creating & Injecting Text Nodes
Text nodes are created automatically for us when a browser
interputs an HTML document and a corresponding DOM is built based on the
contents of the document. After this fact, its also possible to
programatically create Text nodes using
createTextNode(). In the code below I create a text node and
then inject that node into the live DOM tree.
<!DOCTYPE html>
<html lang="en">
<body>
<div></div>
<script>
var textNode = document.createTextNode('Hi');
document.querySelector('div').appendChild(textNode);
console.log(document.querySelector('div').innerText); // logs Hi
</script>
</body>
</html>
Keep in mind that we can also inject text nodes into programmatically
created DOM structures as well. In the code below I place a text node
inside of an <p> element before I inject it into the live
DOM.
7.5 Getting a Text node value with .data or
nodeValue
The text value/data represented by a Text node can be extracted
from the node by using the .data or
nodeValue property. Both of these return the text contained in
a Text node. Below I demostrate both of these to retrive the
value contained in the <div>.
Notice that the <p> contains two Text node and
Element (i.e. <strong>)node. And that we are
only getting the value of the first child node contained in the
<p>.
Notes
Getting the length of the characters contained in a text node is as
simple as accessing the length proerty of the node itself or the
actual text value/data of the node (i.e.
document.querySelector('p').firstChild.length or
document.querySelector('p').firstChild.data.length or
document.querySelector('p').firstChild.nodeValue.length)
7.6 Maniputlating Text nodes with appendData(),
deleteData(), insertData(), replaceData(),
subStringData()
The CharacterData object that Text nodes inherits
methods from provides the following methods for manipulating and
extracting sub values from Text node values.
appendData()
deleteData()
insertData()
replaceData()
subStringData()
Each of these are leverage in the code example below.
These same manipulation and sub extraction methods can be leverage by
Comment nodes
7.7 When mulitple sibling Text nodes occur
Typically, immediate sibling Text nodes do not occur because
DOM trees created by browsers intelligently combines text nodes, however
two cases exist that make sibling text nodes possible. The first case is
rather obvious. If a text node contains an Element node (e.g.
<p>Hi, <strong>cody</strong> welcome!</p>) than the text will be split into the proper node groupings. Its best
to look at a code example as this might sound more complicted than it
really is. In the code below the contents of the
<p> element is not a single Text node it is in
fact 3 nodes, a Text node, Element node, and another
Text node.
<!DOCTYPE html>
<html lang="en">
<body>
<p>Hi, <strong>cody</strong> welcome!</p>
<script>
var pElement = document.querySelector('p');
console.log(pElement.childNodes.length); //logs 3
console.log(pElement.firstChild.data); // is text node or 'Hi, '
console.log(pElement.firstChild.nextSibling); // is Element node or <strong>
console.log(pElement.lastChild.data); // is text node or ' welcome!'
</script>
</body>
</html>
The next case occurs when we are programatically add Text nodes
to an element we created in our code. In the code below I create a
<p> element and then append two Text nodes to
this element. Which results in sibling Text nodes.
7.8 Remove markup and return all child Text nodes using
textContent
The textContent property can be used to get all child text
nodes, as well as to set the contents of a node to a specific
Text node. When its used on a node to get the textual content
of the node it will returned a concatenataed string of all text nodes
contained with the node you call the method on. This functionality would
make it very easy to extract all text nodes from an HTML document. Below
I extract all of the text contained withing the
<body> element. Notice that textContent gathers
not just immediate child text nodes but all child text nodes no matter
the depth of encapsulation inside of the node the method is called.
live code: N/A
<!DOCTYPE html>
<html lang="en">
<body>
<h1> Dude</h2>
<p>you <strong>rock!</strong></p>
<script>
console.log(document.body.textContent); //logs 'Dude you rock!' with some added white space
</script>
</body>
</html>
When textContent is used to set the text contained within a
node it will remove all child nodes first, replacing them with a single
Text node. In the code below I replace all the nodes inside of
the <div> element with a single Text node.
textContent returns null if used on the a document
or doctype node.
textContent returns the contents from
<script> and <style> elements
7.9 The difference between textContent & innerText
Most of the modern bowser, except Firefox, support a seeminly similiar
property to textContent named innerText. However these
properties are not the same. You should be aware of the following
differences between textContent & innerText.
innerText is aware of CSS. So if you have hidden text
innerText ignores this text, whereas
textContent will not
Because innerText cares about CSS it will trigger a reflow,
whereas textContent will not
innerText ignores the Text nodes contained in
<script> and <style> elements
innerText, unlike textContent will normalize the
text that is returned. Just think of textContent as returning
exactly what is in the document with the markup removed. This will
include white space, line breaks, and carriage returns
innerText is considered to be non-standard and browser
specific while textContent is implemented from the DOM
specifications
If you you intend to use innerText you'll have to create a work
around for Firefox.
7.10 Combine sibling Text nodes into one text node using
normalize()
Sibling Text nodes are typically only encountered when text is
programaticly added to the DOM. To eliminate sibling Text nodes
that contain no Element nodes we can use normalize().
This will concatenate sibling text nodes in the DOM into a single
Text node. In the code below I create sibling text, append it
to the DOM, then normalize it.
<!DOCTYPE html>
<html lang="en">
<body>
<div></div>
<script>
var pElementNode = document.createElement('p');
var textNodeHi = document.createTextNode('Hi');
var textNodeCody = document.createTextNode('Cody');
pElementNode.appendChild(textNodeHi);
pElementNode.appendChild(textNodeCody);
document.querySelector('div').appendChild(pElementNode);
console.log(document.querySelector('p').childNodes.length); //logs 2
document.querySelector('div').normalize(); //combine our sibling text nodes
console.log(document.querySelector('p').childNodes.length); //logs 1
</script>
</body>
</html>
7.11 Splitting a text node using splitText()
When splitText() is called on a Text node it will
alter the text node its being called on (leaving the text up to the
offset) and return a new Text node that contains the text split
off from the orginal text based on the offset. In the code below the
text node Hey Yo! is split after Hey and
Hey is left in the DOM while Yo! is turned into a new
text node are returned by the splitText() method.
<!DOCTYPE html>
<html lang="en">
<body>
<p>Hey Yo!</p>
<script>
//returns a new text node, taken from the DOM
console.log(document.querySelector('p').firstChild.splitText(4).data); //logs Yo!//What remains in the DOM... console.log(document.querySelector('p').firstChild.textContent); //logs Hey
</script>
</body>
</html>
Chapter 8 - DocumentFragment Nodes
8.1 DocumentFragment object overview
The creation and use of a DocumentFragment node provides a
light weight document DOM that is external to the live DOM tree. Think
of a DocumentFragment as an empty document template that acts
just like the live DOM tree, but only lives in memory, and its child
nodes can easily be manipulated in memory and then appended to the live
DOM.
8.2 Creating DocumentFragment's using
createDocumentFragment()
In the code below a DocumentFragment is created using
createDocumentFragment() and <li>'s are appended
to the fragment.
Using a documentFragment to create node structures in memory is
extrememly efficent when it comes time to inject the
documentFragment into live node structures.
You might wonder what is the advantage to using a
documentFragment over simply creating (via
createElement()) a <div> in memory and working
within this <div> to create a DOM structure. The follow
are the differences.
A document fragment may contain any kind of node (except
<body> or <html>) where as an element
may not
The document fragment itself, is not added to the DOM when you append
a fragment. The contents of the node are. As opposed to appending an
element node in which the element itself is part of the appending.
When a document fragment is appended to the DOM it transfers from the
document fragment to the place its appended. Its no longer in memory
in the place you created it. This is not true for element nodes that
are temperately used to contained nodes briefly and then are moved to
the live DOM.
8.3 Adding a DocumentFragment to the live DOM
By passing the appendChild() and insertBefore() node
methods a documentFragment argument the child nodes of the
documentFragment are transported as children nodes to the DOM
node the methods are called on. Below we create a
documentfragment, add some <li>'s to it, then
append these new element nodes to the live DOM tree using
appendChild().
Document fragments passed as arguments to inserting node methods will
insert the entire child node structure ignoring the documentFragment
node itself.
8.4 Using innerHTML on a documentFragment
Creating a DOM structure in memory using node methods can be verbose and
laboring. One way around this would be to created a
documentFragment, append a <div> to this
fragment because innerHTML does not work on document fragments,
and then use the innerHTML property to update the fragment with
a string of HTML. By doing this a DOM structure is crafted from the HTML
string. In the code below I construct a DOM structure that I can then
treat as a tree of nodes and not just a JavaScript string.
<!DOCTYPE html>
<html lang="en">
<body>
<script>
//create a <div> and document fragment
var divElm = document.createElement('div'); var docFrag = document.createDocumentFragment(); //append div to document fragment docFrag.appendChild(divElm);
//create a DOM structure from a string
docFrag.querySelector('div').innerHTML = '<ul><li>foo</li><li>bar</li></ul>'; //the string becomes a DOM structure I can call methods on like querySelectorAll()//Just don't forget the DOM structure is wrapped in a <div>
console.log(docFrag.querySelectorAll('li').length); //logs 2
</script>
</body>
</html>
When it comes time to append a DOM structure created using a
documentFragment and <div> you'll want to append
the structure skipping the injection of the <div>.
<!DOCTYPE html>
<html lang="en">
<body>
<div></div>
<script>
//create a <div> and document fragment
var divElm = document.createElement('div'); var docFrag = document.createDocumentFragment(); //append div to document fragment docFrag.appendChild(divElm);
//create a DOM structure from a string
docFrag.querySelector('div').innerHTML = '<ul><li>foo</li><li>bar</li></ul>'; //append, starting with the first child node contained inside of the <div>
document.querySelector('div').appendChild(docFrag.querySelector('div').firstChild);
//logs <ul><li>foo</li><li>bar</li></ul>
console.log(document.querySelector('div').innerHTML);
</script>
</body>
</html>
Notes
In addtion to DocumentFragment we also have
DOMParser
to look forward too. DOMParser can parse HTML stored in a
string into a DOM Document. It's only supported in Opera & Firefox as of today, but a
polyfill is avaliable.
Of course, if you need a stand alone HTML to DOM script try
domify.
8.5 Leaving a fragments containing nodes in memory by cloning
When appending a documentFragment the nodes contained in the
Fragment are moved from the Fragment to the structure you are appending
too. To leave the contents of a fragment in memory, so the nodes remain
after appending, simply clone using cloneNode() the
documentFragment when appending. In the code below instead of
tranporting the <li>'s from the document fragment I clone
the <li>'s, which keeps the <li>'s being
clonded in memory inside of the documentFragment node.
<!DOCTYPE html>
<html lang="en">
<body>
<ul></ul>
<script>
//create ul element and document fragment
var ulElm = document.querySelector('ul'); var docFrag = document.createDocumentFragment(); //append li's to document fragment ["blue", "green", "red", "blue", "pink"].forEach(function(e) { var li = document.createElement("li"); li.textContent = e; docFrag.appendChild(li); }); //append cloned document fragment to ul in live DOM
ulElm.appendChild(docFrag.cloneNode(true));
//logs <li>blue</li><li>green</li><li>red</li><li>blue</li><li>pink</li> console.log(document.querySelector('ul').innerHTML);
//logs [li,li,li,li,li]
console.log(docFrag.childNodes);
</script>
</body>
</html>
Chapter 9 - CSS Style Sheets & CSS rules
9.1 CSS Style sheet overview
A style sheet is added to an HTML document by either using the
HTMLLinkElement node (i.e.
<link href="stylesheet.css" rel="stylesheet"
type="text/css">) to include an external style sheet or the
HTMLStyleElement node (i.e.
<style></style>) to define a style sheet inline. In
the HTML document below both of these Element node's are in the
DOM and I verify which constructor, constructs these nodes.
Once a style sheet is added to an HTML document its represented by the
CSSStylesheet object. Each CSS rule (e.g.
body{background-color:red;}) inside of a style sheet is
represent by a CSSStyleRule object. In the code below I verify
which constructor constructed the style sheet and each CSS rule
(selector & its css properties and values) in the style sheet.
<!DOCTYPE html>
<html lang="en">
<head>
<style id="styleElement">
body{background-color:#fff;}
</style>
</head>
<body>
<script>
//logs function CSSStyleSheet() { [native code] } because this object is the stylesheet itself
console.log(document.querySelector('#styleElement').sheet.constructor);
//logs function CSSStyleRule() { [native code] } because this object is the rule inside of the style sheet
console.log(document.querySelector('#styleElement').sheet.cssRules[0].constructor);
</script>
</body>
</html>
Keep in mind that selecting the element that includes the style sheet
(i.e. <link> or <style>) is not the same
as accessing the actual object (CSSStyleSheet) that represents
the style sheet itself.
9.2 Accessing all style sheets (i.e. CSSStylesheet objects) in
the DOM
document.styleSheets gives access to a list of all style sheet
objects (aka CSSStylesheet) explicitly linked (i.e.
<link>) or embedded (i.e. <style>) in an
HTML document. In the code below styleSheets is leverage to
gain access to all of the style sheets contained in the document.
The length property returns the number of stylesheets
contained in the list starting at 0 index (i.e.
document.styleSheets.length)
The style sheets included in a styleSheets list typically
includes any style sheets created using the
<style> element or using a
<link> element where rel is set to
"stylesheet"
In addtion to using styleSheets to access a documents styles
sheets its also possible to access a style sheet in an HTML document by
first selecting the element in the DOM (<style> or
<link>) and using the .sheet property to gain
access to the CSSStyleSheet object. In the code below I access
the style sheets in the HTML docment by first selecting the element used
to include the style sheet and then leveraging the
sheet property.
<!DOCTYPE html>
<html lang="en">
<head>
<link id="linkElement" href="http://yui.yahooapis.com/3.3.0/build/cssreset/reset-min.css" rel="stylesheet" type="text/css">
<style id="styleElement">
body{background-color:#fff;}
</style>
</head>
<body>
<script>
//get CSSStylesheeet object for <link>
console.log(document.querySelector('#linkElement').sheet); //same as document.styleSheets[0]//get CSSSstylesheet object for <style>
console.log(document.querySelector('#styleElement').sheet); //same as document.styleSheets[1]
</script>
</body>
</html>
9.3 CSSStyleSheet properties and methods
To get accurate information pertaining to the available properties and
methods on an CSSStyleSheet node its best to ignore the
specification and to ask the browser what is available. Examine the
arrays created in the code below detailing the properties and methods
available from a CSSStyleSheet node.
</head>
<body>
<script>
var styleSheet = document.querySelector('#styleElement').sheet;
//text own properties
console.log(Object.keys(styleSheet).sort());
//text own properties & inherited properties
var styleSheetPropertiesIncludeInherited = [];
for(var p in styleSheet){
styleSheetPropertiesIncludeInherited.push(p);
}
console.log(styleSheetPropertiesIncludeInherited.sort());
//text inherited properties only
var styleSheetPropertiesOnlyInherited = [];
for(var p in styleSheet){
if(!styleSheet.hasOwnProperty(p)){
styleSheetPropertiesOnlyInherited.push(p);
}
}
console.log(styleSheetPropertiesOnlyInherited.sort());
</script>
</body>
</html>
A CSSStyleSheet object accessed from a
styleSheets list or via the .sheet property has the
following properties and methods:
disabled
href
media
ownerNode
parentStylesheet
title
type
cssRules
ownerRule
deleteRule
inserRule
Notes
href, media, ownerNode,
parentStylesheet, title, and type are read
only properties, you can't set its value using these properteis
9.4 CSSStyleRule overview
A CSSStyleRule object represents each CSS rule contained in a
style sheet. Basicly a CSSStyleRule is the interface to the CSS
properties and values attached to a selector. In the code below we
programaticlly access the details of each rule contained in the inline
style sheet by accessing the CSSStyleRule object that
represents the CSS rule in the style sheet.
<!DOCTYPE html>
<html lang="en">
<head>
<style id="styleElement">
body{background-color:#fff;margin:20px;} /*this is a css rule*/
p{line-height:1.4em; color:blue;} /*this is a css rule*/
</style>
</head>
<body>
<script>
var sSheet = document.querySelector('#styleElement');
console.log(sSheet.cssRules[0].cssText); //logs "body { background-color: red; margin: 20px; }"
console.log(sSheet.cssRules[1].cssText); //logs "p { line-height: 1.4em; color: blue; }"
</script>
</body>
</html>
9.5 CSSStyleRule properties and methods
To get accurate information pertaining to the available properties and
methods on an CSSStyleRule node its best to ignore the
specification and to ask the browser what is available. Examine the
arrays created in the code below detailing the properties and methods
available from a CSSStyleRulenode.
</head>
<body>
<script>
var styleSheetRule = document.querySelector('#styleElement').sheet.cssRule;
//text own properties
console.log(Object.keys(styleSheetRule).sort());
//text own properties & inherited properties
var styleSheetPropertiesIncludeInherited = [];
for(var p in styleSheetRule){
styleSheetRulePropertiesIncludeInherited.push(p);
}
console.log(styleSheetRulePropertiesIncludeInherited.sort());
//text inherited properties only
var styleSheetRulePropertiesOnlyInherited = [];
for(var p in styleSheetRule){
if(!styleSheetRule.hasOwnProperty(p)){
styleSheetRulePropertiesOnlyInherited.push(p);
}
}
console.log(styleSheetRulePropertiesOnlyInherited.sort());
</script>
</body>
</html>
Scripting the rules (e.g. body{background-color:red;})
contained inside of a style sheet is made possible by the
CSSrule object. This object provides the following properties:
cssText
parentRule
parentStylesSheet
selectorText
style
type
9.6 Getting a list of CSS Rules in a style sheet using CSSRules
As previously discussed the styleSheets list provides a list of
style sheets contained in a document. The CSSRules list
provides a list (aka CSSRulesList) of all the CSS rules (i.e.
CSSStyleRule objects) in a specific style sheet. The code below
logs a CSSRules list to the console.
<!DOCTYPE html>
<html lang="en">
<head>
<style id="styleElement">
body{background-color:#fff;margin:20px;}
p{line-height:1.4em; color:blue;}
</style>
</head>
<body>
<script>
var sSheet = document.querySelector('#styleElement').sheet;
//array like list containing all of the CSSrule objects repreesenting each CSS rule in the style sheet
console.log(sSheet.cssRules);
console.log(sSheet.cssRules.length); //logs 2//rules are index in a CSSRules list starting at a 0 index
console.log(sSheet.cssRules[0]); //logs first rule
console.log(sSheet.cssRules[1]); //logs second rule
</script>
</body>
</html>
9.7 Inserting & deleting CSS rules in a style sheet using
.insertRule() and .deleteRule()
The insertRule() and deleteRule() methods provided the
ability to programatically manipulate the CSS rules in a style sheet. In
the code below I use insertRule() to add the css rule
p{color:red} to the inline style sheet at index 1. Remeber the
css rules in a style sheet are numerical index starting at 0. So by
inserting a new rule at index 1 the current rule at index 1 (i.e.
p{font-size:50px;}) is push to index 2.
<!DOCTYPE html>
<html lang="en">
<head>
<style id="styleElement">
p{line-height:1.4em; color:blue;} /*index 0*/
p{font-size:50px;} /*index 1*/
</style>
</head>
<body>
<p>Hi</p>
<script>
//add a new CSS rule at index 1 in the inline style sheet
document.querySelector('#styleElement').sheet.insertRule('p{color:red}',1);
//verify it was added console.log(document.querySelector('#styleElement').sheet.cssRules[1].cssText);
//Delete what we just added
document.querySelector('#styleElement').sheet.deleteRule(1);
//verify it was removed console.log(document.querySelector('#styleElement').sheet.cssRules[1].cssText);
</script>
</body>
</html>
Deleting or removing a rule is as simple as calling
deleteRule() method on a style sheet and passing it the index
of the rule in the style sheet to be deleted.
Notes
Inserting and deleting rules is not a common practice given the
difficulty around managing the cascaade and using a numeric indexing
system to update a style sheet (i.e. determining at what index a style
is located without previewing the contents of the style sheet
itself.). Its much simpler working with CSS rules in CSS and HTML
files before they are served to a client than programaticlly altering
them in the client after the fact.
9.8 Editing the value of a CSSStyleRule using the
.style property
Just like the .style property that facilitates the manipulation
of inline styles on element nodes there is a also
.style property for CSSStyleRule objects that
orchestrates the same manipulation of styles in style sheets. In the
code below I levereage the .style property to set and get the
value of css rules contained in the inline style sheet.
To craft a new style sheet on the fly after an html page is loaded one
only has to create a new <style> node, add CSS rules
using innerHTML to this node, then append the
<style>
node to the HTML document. In the code below I programatily craft a
style sheet and add the body{color:red} CSS rule to the style
sheet, then append the stylesheet to the DOM.
<!DOCTYPE html>
<html lang="en">
<head></head>
<body>
<p>Hey <strong>Dude!</strong></p>
<script>
var styleElm = document.createElement('style');
styleElm.innerHTML = 'body{color:red}';//notice markup in the document changed to red from our new inline stylesheet
document.querySelector('head').appendChild(styleElm);
</script>
</body>
</html>
9.10 Programatically adding external style sheets to an HTML document
To add a CSS file to an HTML document programatically a
<link> element node is created with the appropriate
attributes and then the <link> element node is appended
to the DOM. In the code below I programatically include an external
style sheet by crafting a new <link> element and
appending it to the DOM.
<!DOCTYPE html>
<html lang="en">
<head></head>
<body>
<script>
//create & add attributes to <link>var linkElm = document.createElement('link'); linkElm.setAttribute('rel', 'stylesheet'); linkElm.setAttribute('type', 'text/css');
linkElm.setAttribute('id', 'linkElement'); linkElm.setAttribute('href', 'http://yui.yahooapis.com/3.3.0/build/cssreset/reset-min.css');//Append to the DOM
document.head.appendChild(linkElm);
//confrim its addition to the DOM
console.log(document.querySelector('#linkElement'));
</script>
</body>
</html>
9.11 Disabling/Enabling style sheets using disabled property
Using the .disabled property of a CSSStyleSheet object
its possible to enable or disabled a style sheet. In the code below we
access the current disabled value of each style sheet in the document
then proceed to disabled each style sheet leveraging the
.disabled property.
<!DOCTYPE html>
<html lang="en">
<head>
<link id="linkElement" href="http://yui.yahooapis.com/3.3.0/build/cssreset/reset-min.css" rel="stylesheet" type="text/css">
<style id="styleElement">
body{color:red;}
</style>
</head>
<body>
<script>
//Get current boolean disabled value
console.log(document.querySelector('#linkElement').disabled); //log 'false'
console.log(document.querySelector('#styleElement').disabled); //log 'false'//Set disabled value, which of courese disabled all styles for this document
document.document.querySelector('#linkElement').disabled = true;
document.document.querySelector('#styleElement').disabled = true;
</script>
</body>
</html>
Notes
Disabled is not an avaliable attributre of a <link> or
<style> element according to the specification. Trying to add
this as an attribute in the HTML document itself will fail (and likley
cause parsing errors where styles are ignored) in the majority of
modern browsers in use today.
Chapter 10 - JavaScript in the DOM
10.1 Inserting & executing JavaScript overview
JavaScript can be inserted in to an HTML document in a modern way by
including external JavaScript files or writing page level inline
JavaScript, which is basically the contents of an external JavaScript
file literally embed in the HTML page as a text node. Don't confuse
element inline JavaScript contained in attribute event handlers (i.e.
<div onclick="alert('yo')"></div>) with
page inline JavaScript (i.e.
<script>alert('hi')</script>).
Both methods of inserting JavaScript into an HTML document require the
use of a
<script>
element node. The <script> element can contain JavaScript code or
can be used to link to external JavaScript files using the
src attribute. Both methods are explored in the code example
below.
Its possible to insert and execute JavaScript in the DOM by placing
JavaScript in an element attribute event handler (i.e.
<div onclick="alert('yo')"></div>) and
using the javascript: protocal (e.g.
<a href="javascript:alert('yo')"></a>)
but this is no longer considered a modern practice.
Trying to include an external JavaScript file and writing page inline
JavaScript using the same <script> element will result
in the page inline JavaScript being ignored and the exterenal
JavaScript file being downloaded and exectued
Self-closing scripts tags (i.e.
<script src="" /> ) should be avoid unless
you are rocking some old school XHTML
The <script> element does not have any required
attributes but offers the follow optional attribures: async,
charset, defer, src, and type
Page inline JavaScript produces a text node. Which permits the usage
of innerHTML and textContent to retrieve the
contents of a line <script>. However, appending a new
text node made up of JavaScript code to the DOM after the browser has
already parsed the DOM will not execute the new JavaScript code. It
simply replaces the text.
If JavaScript code contains the string '</script>' you
will have to escape the closing '/' with
'<\/script>' so that the parser does not think this is
the real closing </script> element
10.2 JavaScript is parsed synchronously by default
By default when the DOM is being parsed and it encounters a
<script> element it will stop parsing the document, block
any further rendering & downloading, and exectue the JavaScript.
Because this behavior is blocking and does not permit parallel parsing
of the DOM or exection of JavaScriopt its consider to be synchronous. If
the JavaScript is external to the html document the blocking is
exacerbated because the JavaScript must first be downloaed before it can
be parsed. In the code example below I comment what is occuring during
browser rendering when the browser encoutners several
<script> elements in the DOM.
You should make note of the differences between an inline script's and
external scripts as it pertains to the loading phase.
Notes
The default blocking nature of a <script> element can
have a significant effect on the perfomrance & percived
performance of the visual rendering of a HTML web page. If you have a
couple of script elements at the start of an html page nothing else is
happening (e.g. DOM parsing & resource loading) until each one is
downloaed and executed sequentially.
10.3 Defering the downloading & exectuion of external JavaScript
using defer
The <script> element has an attribute called
defer that will defer the blocking, downloading, and executing
of an external JavaScript file until the browser has parsed the closing
<html> node. Using this attribute simply defers what
normally occurs when a web browser encoutners a
<script> node. In the code below I defer each external
JavaScript file until the final <html> is encountered.
<!DOCTYPE html>
<html lang="en">
<body>
<!-- defer, don't block just ignore this until the <html> element node is parsed -->
<script defer src="http://cdnjs.cloudflare.com/ajax/libs/underscore.js/1.3.3/underscore-min.js"></script><!-- defer, don't block just ignore this until the <html> element node is parsed -->
<script defer src="http://cdnjs.cloudflare.com/ajax/libs/jquery/1.7.2/jquery.min.js"></script>
<!-- defer, don't block just ignore this until the <html> element node is parsed -->
<script defer src="http://cdnjs.cloudflare.com/ajax/libs/jquery-mousewheel/3.0.6/jquery.mousewheel.min.js"></script>
<script>
//We know that jQuery is not avaliable because this occurs before the closing <html> element
console.log(window['jQuery'] === undefined); //logs true//Only after everything is loaded can we safley conclude that jQuery was loaded and parsed
document.body.onload = function(){console.log(jQuery().jquery)}; //logs function
</script>
</body>
</html>
Notes
According to the specification defered scripts are suppose to be
exectued in document order and before the
DOMContentLoaded event. However, adherence to this
specification among modern browsers is inconsistent.
defer is a boolan attribute it does not have a value
Some browers support defered inline scripts but this is not common
among modern browsers
By using defer the assummption is that
document.write() is not being used in the JavaScript that
will be defered
10.4 Asynchronously downloading & executing external JavaScript
files using async
The <script> element has an attribute called
async that will override the sequential blocking nature of
<script> elements when the DOM is being constructed by a
web browser. By using this attribute, we are telling the browser not to
block the construction (i.e. DOM parsing, including downloading other
assets e.g. images, style sheets, etc...) of the html page and forgo the
the sequential loading as well.
What happens by using the async attribute is the files are
loaded in parallel and parsed in order of download once they are fully
downloaded. In the code below I comment what is happening when the HTML
document is being parsed and render by the web browser.
<!DOCTYPE html>
<html lang="en">
<body>
<!-- Don't block, just start downloading and then parse the file when it's done downloading -->
<script async src="http://cdnjs.cloudflare.com/ajax/libs/underscore.js/1.3.3/underscore-min.js"></script><!-- Don't block, just start downloading and then parse the file when it's done downloading -->
<script async src="http://cdnjs.cloudflare.com/ajax/libs/jquery/1.7.2/jquery.min.js"></script>
<!-- Don't block, just start downloading and then parse the file when it's done downloading -->
<script async src="http://cdnjs.cloudflare.com/ajax/libs/jquery-mousewheel/3.0.6/jquery.mousewheel.min.js"></script>
<script>
// we have no idea if jQuery has been loaded yet likley not yet...
console.log(window['jQuery'] === undefined);//logs true//Only after everything is loaded can we safley conclude that jQuery was loaded and parsed
document.body.onload = function(){console.log(jQuery().jquery)};
</script>
</body>
</html>
Notes
IE 10 has support for async, but IE 9 does not
A major drawback to using the async attribute is JavaScript
files potentially get parsed out of the order they are included in the
DOM. This raises a dependency management issue.
async is a boolan attribute it does not have a value
By using async the assummption is that
document.write() is not being used in the JavaScript that
will be defered
The async attribute will trump the defer if both are
used on a <script> element
10.5 Forcing asynchronous downloading & parsing of external
JavaScript using dynamic <script>
A known hack for forcing a web browser into asynchronous JavaScript
downloading and parsing without using the async attribure is to
programatically create <script> elements that include
external JavaScript files and insert them in the DOM. In the code below
I programatically create the <script> element node and
then append it to the <body> element which forces the
browser to treat the <script> element asynchronously.
<!DOCTYPE html>
<html lang="en">
<body>
<!-- Don't block, just start downloading and then parse the file when it's done downloading -->
<script>
var underscoreScript = document.createElement("script");
underscoreScript.src = "http://cdnjs.cloudflare.com/ajax/libs/underscore.js/1.3.3/underscore-min.js";
document.body.appendChild(underscoreScript);
</script>
<!-- Don't block, just start downloading and then parse the file when it's done downloading -->
<script>
var jqueryScript = document.createElement("script");
jqueryScript.src = "http://cdnjs.cloudflare.com/ajax/libs/jquery/1.7.2/jquery.min.js";
document.body.appendChild(jqueryScript);
</script>
<!-- Don't block, just start downloading and then parse the file when it's done downloading -->
<script>
var mouseWheelScript = document.createElement("script");
mouseWheelScript.src = "http://cdnjs.cloudflare.com/ajax/libs/jquery-mousewheel/3.0.6/jquery.mousewheel.min.js";
document.body.appendChild(mouseWheelScript);
</script>
<script>
//Only after everything is loaded can we safley conclude that jQuery was loaded and parsed
document.body.onload = function(){console.log(jQuery().jquery)};
</script>
</body>
</html>
Notes
A major drawback to using dynamic <script> elements is
JavaScript files potentially get parsed out of the order they are
included in the DOM. This raises a dependency management issue.
10.6 Using the onload call back for asynchronous
<script>'s so we know when its loaded
The <script> element
supports a load event
handler (ie. onload) that will execute once an external
JavaScript file has been loaded and executed. In the code below I
leverage the onload event to create a callback programatically
notifying us when the JavaScript file has been downloaded and exectued.
<!DOCTYPE html>
<html lang="en">
<body>
<!-- Don't block, just start downloading and then parse the file when it's done downloading -->
<script>
var underscoreScript = document.createElement("script");
underscoreScript.src = "http://cdnjs.cloudflare.com/ajax/libs/underscore.js/1.3.3/underscore-min.js";
underscoreScript.onload = function(){console.log('underscsore is loaded and exectuted');};
document.body.appendChild(underscoreScript);
</script>
<!-- Don't block, just start downloading and then parse the file when it's done downloading -->
<script async src="http://cdnjs.cloudflare.com/ajax/libs/jquery/1.7.2/jquery.min.js" onload="console.log('jQuery is loaded and exectuted');"></script>
</body>
</html>
10.7 Be mindful of <script> 's placement in HTML for DOM
manipulation
Given a <script> elements synchronous nature, placing one
in the <head> element of an HTML document presents a
timing problem if the JavaScript execution is dependant upon any of the
DOM that proceeds the <script>. In a nut shell, if
JavaScript is executed at the begining of a document that manipulates
the DOM, that proceeds it, you are going to get a JavaScript error.
Proven by the following code example:
live code: N/A
<!DOCTYPE html>
<html lang="en">
<head>
<!-- stop parsing, block parsing, exectue js then resume... -->
<script>
//we can't script the body element yet, its null, not even been parsed by the browser, its not in the DOM yet console.log(document.body.innerHTML);//logs Uncaught TypeError: Cannot read property 'innerHTML' of null
</script>
</head>
<body>
<strong>Hi</strong>
</body>
</html>
Many developers, myself being one of them, for this reason will attempt
to place all <script> elements before the closing
</body> element. By doing this you can rest assured the
DOM in front of the <script>'s has been parsed and is
ready for scripting. As well, this strategy will remove a dependancy on
DOM ready events that can liter a code base.
10.8 Getting a list of <script>'s in the DOM
The document.scripts property avaliable from the document
object provides a list (i.e. an HTMLCollection) of all of the
scripts currently in the DOM. In the code below I leverage this property
to gain access to each of the <script> elements
src attributes.
live code: N/A
<!DOCTYPE html>
<html lang="en">
<body>
<script src="http://cdnjs.cloudflare.com/ajax/libs/underscore.js/1.3.3/underscore-min.js"></script>
<script src="http://cdnjs.cloudflare.com/ajax/libs/jquery/1.7.2/jquery.min.js"></script>
<script src="http://cdnjs.cloudflare.com/ajax/libs/jquery-mousewheel/3.0.6/jquery.mousewheel.min.js"></script>
<script>
Array.prototype.slice.call(document.scripts).forEach(function(elm){ console.log(elm); });//will log each script element in the document
</script>
</body>
</html>
Chapter 11 - DOM Events
11.1 DOM events overview
An event, in terms of the DOM, is either a pre-defined or custom moment
in time that occurs in relationship with an element in the DOM, the
document object, or the window object. These moments
are typically predetermined and programaticlly accounted for by
associating functionality (i.e. handlers/callbacks) to occur when these
moments in time come to pass. These moments can be initiated by that
state of the UI (e.g. input is focused or something has been dragged),
the state of the enviroment that is running the JavaScript program (e.g.
page is loaded or XHR request has finished), or the state of the program
itself (e.g. start monitor users ui interaction for 30 seconds after the
page has loaded).
Setting up events can be accomplished using inline attribute event
handlers, property event handlers, or the
addEventListener() method. In the code below I'm demonstrating
these three patterns for setting up an event. All three patterns add a
click event that is invoked whenever the
<div> in the html document is clicked by the mouse.
Notice that one of the events is attached to the
<body> element. If you find it odd that the attribute
event handler on the <body> fires by clicking the
<div> element consider that when the
<div> is clicked, are you not also clicking on the
<body> element. Click anywhere but on the
<div> and you still see the attribute handler fire on the
<body> element alone.
While all three of these patterns for attaching an event to the DOM
programatically schedule the event, only the
addEventListener() provides a robust and organized solution.
The inline attribute event handler mixes together JavaScript and HTML
and best practices advise keeping these things seperate.
The downside to using a property event handler is that only one value
can be assigned to the event property at a time. Meaning, you can't add
more than one propety event handler to a DOM node when assigning events
as property values. The code below shows an example of this by assigning
a value to the onclick property twice, the last value set is
used when the event is invoked.
<!DOCTYPE html>
<html lang="en">
<body>
<div>click me</div>
<script>
var elementDiv = document.querySelector('div');
// property event handler
elementDiv.onclick = function(){console.log('I\'m first, but I get overidden/replace')};
//overrides/replaces the prior value
elementDiv.onclick = function(){console.log('I win')};
</script>
</body>
</html>
Additionaly, using event handlers inline or property event handlers can
suffer from scoping nuances as one attempts to leverage the scope chain
from the function that is invoked by the event. The
addEventListener() smooths out all of these issues, and will be
used throughout this chapter.
Notes
Element nodes typically support inline event handlers (e.g.
<div onclick=""></div>), property event
handlers (e.g.
document.querySelector('div').onclick = function(){}), and
the use of the addEventListener() method.
The Document node supports property event handlers (e.g.
document.onclick = funciton()) and the use of the addEventListener() method.
The window object supports inline event handler's via the
<body> or <frameset> element (e.g.
<body onload=""></body>), property
event handlers (e.g. window.load = function(){}), and the use
of the addEventListener() method.
A property event handler historically has been refered to as a
"DOM level 0 event". And the addEventListener() is
often refered to as a "DOM level 2 event". Which is rather
confusing considering there is no level 0 event or level 1 event.
Addintioanlly, inline event handlers are known to be called,
"HTML event handlers".
11.2 DOM event types
In the tables below I detail the most common pre-defined events that can
be attached to Element nodes, the document object, and
the window object. Of course not all events are directly
applicable to the node or object it can be attached too. That is, just
because you can attach the event without error, and most likley invoke
the event (i.e. bubbling events like onchange to
window), does not mean that adding something like
window.onchange is logical given that this event, by design
was not meant for the window object.
User interface events
Event Type
Event Interface
Description
Event Targets
Bubbles
Cancelable
load
Event, UIEvent
fires when an asset (HTML page, image, CSS, frameset,
<object>, or JS file) is loaded.
fires when user agent removes the resource (document, element,
defaultView) or any depending resources (images, CSS file, etc.)
window, <body>, <frameset>
No
No
abort
Event, UIEvent
Fires when an resource (object/image) is stopped from loading
before completely loaded
Element, XMLHttpRequest,
XMLHttpRequestUpload
Yes
No
error
Event, UIEvent
Fires when a resource failed to load, or has been loaded but
cannot be interpreted according to its semantics, such as an
invalid image, a script execution error, or non-well-formed XML
Element, XMLHttpRequest,
XMLHttpRequestUpload
Yes
No
resize
UIEvent
Fires when a document view has been resized. This event type is
dispatched after all effects for that occurrence of resizing of
that particular event target have been executed by the user agent
window, <body>, <frameset>
Yes
No
scroll
UIEvent
Fires when a user scrolls a document or an element.
Element, Document, window
Yes
No
contextmenu
MouseEvent
fires by right clicking an element
Element
Yes
Yes
Focus events
Event Type
Event Interface
Description
Events Targets
Bubbles
Cancelable
blur
FocusEvent
Fires when an element loses focus either via the mouse or tabbing
Element (except <body> and
<frameseet> ), Document
No
No
focus
FocusEvent
Fires when an element receives focus
Element (except <body> and
<frameseet> ), Document
No
No
focusin
FocusEvent
Fires when an event target is about to receive focus but before
the focus is shifted. This event occurs right before the focus
event
Element
Yes
No
focusout
FocusEvent
Fires when an event target is about to lose focus but before the
focus is shifted. This event occurs right before the blur event
Element
Yes
No
Form events
Event Type
Event Interface
Description
Event Targets
Bubbles
Cancelable
change
specific to HTML forms
Fires when a control loses the input focus and its value has been
modified since gaining focus
Element
Yes
No
reset
specific to HTML forms
Fires when a form is reset
Element
Yes
No
submit
specific to HTML forms
Fires when a form is submitted
Element
Yes
Yes
select
specific to HTML forms
Fires when a user selects some text in a text field, including
input and textarea
Element
Yes
No
Mouse events
Event Type
Event Interface
Description
Event Targets
Bubbles
Cancelable
click
MouseEvent
Fires when mouse pointer is clicked (or user presses enter key)
over an element. A click is defined as a mousedown and mouseup
over the same screen location. The sequence of these events is
mousedown>mouseup>click.
Depending upon the environment configuration,
the click event may be dispatched if one or more of the event
types mouseover, mousemove, and mouseout occur between the press
and release of the pointing device button.
The click event may also be followed by the dblclick event
Element, Document, window
Yes
Yes
dblclick
MouseEvent
Fires when a mouse pointer is clicked twice over an element. The
definition of a double click depends on the environment
configuration, except that the event target must be the same
between mousedown, mouseup,
and dblclick. This event type must be dispatched after
the event typeclick if a click and double click occur
simultaneously, and after the event
type mouseup otherwise
Element, Document, window
Yes
Yes
mousedown
MouseEvent
Fires when mouse pointer is pressed over an element
Element, Document, window
Yes
Yes
mouseenter
MouseEvent
Fires when mouse pointer is moved onto the boundaries of an
element or one of its descendent elements. This event type is
similar to mouseover, but differs in that it does not bubble,
and must not be dispatched when the pointer device moves from an
element onto the boundaries of one of its descendent elements
Element, Document, window
No
No
mouseleave
MouseEvent
Fires when mouse pointer is moved off of the boundaries of an
element and all of its descendent elements. This event type is
similar to mouseout, but differs in that does not bubble, and that
it must not be dispatched until the pointing device has left the
boundaries of the element and the boundaries of all of its
children
Element, Document, window
No
No
mousemove
MouseEvent
Fires when mouse pointer is moved while it is over an element. The
frequency rate of events while the pointing device is moved is
implementation-, device-, and platform-specific, but multiple
consecutive mousemove events should be fired for sustained
pointer-device movement, rather than a single event for each
instance of mouse movement. Implementations are encouraged to
determine the optimal frequency rate to balance responsiveness
with performance
Element, Document, window
Yes
No
mouseout
MouseEvent
Fires when mouse pointer is moved off of the boundaries of an
element. This event type is similar to mouseleave, but
differs in that does bubble, and that it must be dispatched when
the pointer device moves from an element onto the boundaries of
one of its descendent elements
Element, Document, window
Yes
Yes
mouseup
MouseEvent
Fires when mouse pointer button is released over an element
Element, Document, window
Yes
Yes
mouseover
MouseEvent
Fires when mouse pointer is moved over an element
Element, Document, window
Yes
Yes
Wheel events
Event Type
Event Interface
Description
Event Targets
Bubbles
Cancelable
wheel (browsers use mousewheel but the
specification uses wheel)
WheelEvent
Fires when a mouse wheel has been rotated around any axis, or when
an equivalent input device (such as a mouse-ball, certain tablets
or touchpads, etc.) has emulated such an action. Depending on the
platform and input device, diagonal wheel deltas may be delivered
either as a singlewheel event with multiple non-zero axes or as
separate wheel events for each non-zero axis. Some helpful details
about browser support can be found
here.
Element, Document, Window
Yes
Yes
Keyboard events
Event Type
Event Interface
Description
Event Targets
Bubbles
Cancelable
keydown
KeyboardEvent
Fires when a key is initially pressed. This is sent after any key
mapping is performed, but before any input method editors receive
the keypress. This is sent for any key, even if it doesn't
generate a character code.
Element, Document
Yes
Yes
keypress
KeyboardEvent
Fires when a key is initially pressed, but only if that key
normally produces a character value. This is sent after any key
mapping is performed, but before any input method editors receive
the keypress.
Element, Document
Yes
Yes
keyup
KeyboardEvent
Fires when a key is released. This is sent after any key mapping
is performed, and always follows thecorresponding
keydown and keypress events.
Element, Document
Yes
Yes
Touch events
Event Type
Event Interface
Description
Event Targets
Bubbles
Cancelable
touchstart
TouchEvent
Fires event to indicate when the user places a touch point on the
touch surface
Element, Document, window
Yes
Yes
touchend
TouchEvent
Fires event to indicate when the user removes a touch point from the touch surface, also including cases where the touch
point physically leaves the touch surface, such as being dragged
off of the screen
Element, Document, window
Yes
Yes
touchmove
TouchEvent
Fires event to indicate when the user moves a touch point along
the touch surface
Element, Document, window
Yes
Yes
touchenter
TouchEvent
Fires event to indicate when a touch point moves onto the
interactive area defined by a DOM element
Element, Document, window
No
?
toucheleave
TouchEvent
Fires event to indicate when a touch point moves off the
interactive area defined by a DOM element
Element, Document, window
No
?
touchcancel
TouchEvent
Fires event to indicate when a touch point has been disrupted in
an implementation-specific manner, such as a synchronous event or
action originating from the UA canceling the touch, or the touch
point leaving the document window into a non-document area which
is capable of handling user interactions.
Element, Document, window
Yes
No
Notes
Touch events are typically only supported iOS, Andorid, and Blackberry
browsers or browsers (e.g. chrome) that can switch on touch modes
Window, <body>, and frame specific events
Event Type
Event Interface
Description
Event Targets
Bubbles
Cancelable
afterprint
?
Fires on the object immediately after its associated document
prints or previews for printing
window, <body>, <frameset>
No
No
beforeprint
?
Fires on the object before its associated document prints or
previews for printing
window, <body>, <frameset>
No
No
beforeunload
?
Fires prior to a document being unloaded
window, <body>, <frameset>
No
Yes
hashchange
HashChangeEvent
Fires when there are changes to the portion of a URL that follows
the number sign (#)
window, <body>, <frameset>
No
No
messsage
?
Fires when the user sends a cross-document message or a message is
sent from a Worker with postMessage
window, <body>, <frameset>
No
No
offline
NavigatorOnLine
Fires when browser is working offline
window, <body>, <frameset>
No
No
online
NavigatorOnLine
Fires when browser is working online
window, <body>, <frameset>
No
No
pagehide
PageTransitionEvent
Fires when traversing from a session history entry
window, <body>, <frameset>
No
No
pageshow
PageTransitionEvent
The pagehide event is fired when traversing from a session history
entry
window, <body>, <frameset>
No
No
Document specific events
Event Type
Event Interface
Description
Event Targets
Bubbles
Cancelable
readystatechange
Event
Fires event when readyState is changed
Document, XMLHttpRequest
No
No
DOMContentLoaded
Event
Fires when a webpage has been parsed, but before all resources
have been fully downloaded
Document
Yes
No
Drag events
Event Type
Event Interface
Description
Event Targets
Bubbles
Cancelable
drag
DragEvent
Fires on the source object continuously during a drag operation.
Element, Document, window
Yes
Yes
dragstart
DragEvent
Fires on the source object when the user starts to drag a text
selection or selected object. The ondragstart event is the first
to fire when the user starts to drag the mouse.
Element, Document, window
Yes
Yes
dragend
DragEvent
Fires on the source object when the user releases the mouse at the
close of a drag operation. The ondragend event is the final drag
event to fire, following the ondragleave event, which fires on the
target object.
Element, Document, window
Yes
No
dragenter
DragEvent
Fires on the target element when the user drags the object to a
valid drop target.
Element, Document, window
Yes
Yes
dragleave
DragEvent
Fires on the target object when the user moves the mouse out of a
valid drop target during a drag operation.
Element, Document, window
Yes
No
dragover
DragEvent
Fires on the target element continuously while the user drags the
object over a valid drop target. The ondragover event fires on the
target object after the ondragenter event has fired.
Element, Document, window
Yes
Yes
drop
DragEvent
Fires on the target object when the mouse button is released
during a drag-and-drop operation. The ondrop event fires before
the ondragleave and ondragend events.
I've only mentioned here in this section the most common event types.
Keep in mind there are numerous HTML5 api's that I've excluded from
the this section (e.g.
media events
for <video> and <audio> elements or all
state change events for the
XMLHttpRequest Level 2).
The copy, cut, and textinput event are not
defined by DOM 3 events or HTML5
Use mouseenter and mouseleave instead of mouseover and mouseout.
Unfortunately Firefox, Chrome, and Safari still haven’t added
these events!
11.3 The event flow
When an event is invoked the
event flows or propagates through the DOM, firing the same event on other nodes and JavaScript objects. The
event flow can be programmed to occur as a capture phase (i.e. DOM tree
trunk to branch) or bubbling phase (i.e. DOM tree branches to trunk), or
both.
In the code below I set up 10 event listeners that can all be invoked,
due to the event flow, by clicking once on the
<div> element in the HTML document. When the
<div> is clicked the capture phase begins at the
window object and propagates down the DOM tree firing the
click event for each object (i.e. window>document><html> > <body> > event target) until it hits the event target.
Once the capture phase ends the target phase starts, firing the
click event on the target element itself. Next the propagation
phase propagates up from the event target firing the
click event until it reaches the window object (i.e.
event target ><body>><html>>document>window). With this
knowledge it should be obvious why clicking the <div> in
the code example logs to the console 1,2,3,4,5,6,7,8,9,11.
<!DOCTYPE html>
<html lang="en">
<body>
<div>click me to start event flow</div>
<script>
/*notice that I am passing the addEventListener() a boolean parameter of true so capture events fire, not just bubbling events*///1 capture phase
window.addEventListener('click',function(){console.log(1);},true);
//2 capture phase
document.addEventListener('click',function(){console.log(2);},true);
//3 capture phase
document.documentElement.addEventListener('click',function(){console.log(3);},true);
//4 capture phase
document.body.addEventListener('click',function(){console.log(4);},true);
//5 target phase occurs during capture phase
document.querySelector('div').addEventListener('click',function(){console.log(5);},true);
//6 target phase occurs during bubbling phase
document.querySelector('div').addEventListener('click',function(){console.log(6);},false);
//7 bubbling phase
document.body.addEventListener('click',function(){console.log(7);},false);
//8bubbling phase
document.documentElement.addEventListener('click',function(){console.log(8);},false);
//9bubbling phase
document.addEventListener('click',function(){console.log(9);},false);
//10bubbling phase
window.addEventListener('click',function(){console.log(10)},false);
</script>
</body>
</html>
After the <div> is clicked, the event flow proceeds in
this order:
capture phase invokes click events on window that are set to fire on
capture
capture phase invokes click events on document that are set to fire on
capture
capture phase invokes click events on html element that are set to
fire on capture
capture phase invokes click events on body element that are set to
fire on capture
target phase invokes click events on div element that are set to fire
on capture
target phase invokes click events on div element that are set to fire
on bubble
bubbling phase invokes click events on body element are set to fire on
bubble
bubbling phase invokes click events on html element are set to fire on
bubble
bubbling phase invokes click events on document are set to fire on
bubble
bubbling phase invokes click events on window are set to fire on
bubble
The use of the capture phase is not all that common due to a lack of
browser support for this phase. Typically events are assumed to be
inovked during the bubbling phase. In the code below I remove the
capture phase from the previous code example and demostrate typically
what is occuring during an event invocation.
Notice in the last code example that if the click event is initiated
(click anywhere except on the <div>) on the
<body> element the click event attached to the
<div> is not invoked and bubbling invocation starts on
the <body>. This is due to the fact the the event target
is no longer the <div> but instead the
<body> element.
Notes
Modern browsers do support the use of the capture phase so what was
once considered unreliable might just server some value today. For
example, one could intercept an event before it occurs on the event
target.
Keep this knowledge of event capturing and bubbling at the forefront
of your thoughts when you read the event delegation section of this
chapter.
The event object passed to event listener functions contains a
eventPhase property containing a number which indicates which
phase an event is inoked in. A value of 1 indicates the capture phase.
A value of 2 indicates the target phase. And a value of 3 indicates
bubbling phase.
11.4 Adding event listeners to Element nodes,
window object, and Document object
The addEventListener() method is avaliabe on all
Element nodes, the window object, and the
document object providing the ability to added event listeners
to parts of an HTML document as well as JavaScript objects relating to
the DOM and
BOM
(browser object model). In the code below I leverage this method to add
a mousemove event to a <div> element, the
document object, and the window object. Notice, due to
the event flow, that mouse movement specifically over the
<div> will invoke all three listeners each to time a
movement occurs.
<!DOCTYPE html>
<html lang="en">
<body>
<div>mouse over me</div>
<script>
//add a mousemove event to the window object, invoking the event during the bubbling phase
window.addEventListener('mousemove',function(){console.log('moving over window');},false);
//add a mousemove event to the document object, invoking the event during the bubbling phase
document.addEventListener('mousemove',function(){console.log('moving over document');},false);
//add a mousemove event to a <div> element object, invoking the event during the bubbling phase
document.querySelector('div').addEventListener('mousemove',function(){console.log('moving over div');},false);
</script>
</body>
</html>
The addEventListener() method used in the above code example
takes three arguments. The first argument is the type of event to listen
for. Notice that the event type string does not contain the
"on" prefix (i.e. onmousemove) that event handlers
require. The second argument is the function to be invoked when the
event occurs. The third parameter is a boolean indicating if the event
should be fired during the capture phase or bubbling phase of the event
flow.
Notes
I've purposfully avoided dicussing inline event handlers &
property event handlers in favor of promoting the use of
addEventListener()
Typically a developer wants events to fire during the bubbling phase
so that object eventing handles the event before bubbling the event up
the DOM. Because of this you almost always provide a
false value as the last argument to the
addEventListener(). In modern browsers if the 3rd parameter
is not specified it will default to false.
You should be aware that the addEventListener() method can be
used on the XMLHttpRequest object
11.5 Removing event listeners
The removeEventListener() method can be used to remove events
listeners, if the orginal listener was not added using an anonymous
function. In the code below I add two events listeners to the HTML
document and attempt to remove both of them. However, only the listener
that was attached using a function reference is removed.
<!DOCTYPE html>
<html lang="en">
<body>
<div>click to say hi</div>
<script>
var sayHi = function(){console.log('hi')};
//adding event listener using anonymous function
document.body.addEventListener('click',function(){console.log('dude');},false);
//adding event listener using function reference
document.querySelector('div').addEventListener('click',sayHi,false);
//attempt to remove both event listeners, but only the listener added with a funtions reference is removed
document.querySelector('div').removeEventListener('click',sayHi,false);
//this of course does not work as the function passed to removeEventListener is a new and different function
document.body.removeEventListener('click',function(){console.log('dude');},false);
//clicking the div will still invoke the click event attached to the body element, this event was not removed
</script>
</body>
</html>
Anonymous functions added using addEventListener() method
simply cannot be removed.
11.6 Getting event properties from the event object
The handler or callback function invoked for events is sent by default a
parameter that contains all relevant information about an event itself.
In the code below I demostrate access to this event object and log all
of its properties and values for a load event as well as a click event.
Make sure you click the <div> to see the properties
assocaited with a click event.
Keep in mind that each event will contain slightly different properties
based on the event type (e.g.
MouseEvent,
KeyboardEvent,
WheelEvent).
Notes
The event object also provides the stopPropagation(),
stopImediatePropagation(), and
preventDefault() methods.
In this book I use the argument name event to reference the
event object. In truth you can use any name you like and its not
uncommon to see e or evt.
11.7 The value of this when using addEventListener()
The value of this inside of the event listener function passed
to the addEventListener() method will be a reference to the
node or object the event is attached too. In the code below I attach an
event to a <div> and then using this inside of
the event listener gain access to the <div> element the
event is attached too.
<!DOCTYPE html>
<html lang="en">
<body>
<div>click me</div>
<script>
document.querySelector('div').addEventListener('click',function(){
// 'this' will be the element or node the event listener is attached too
console.log(this); //logs '<div>'
},false);
</script>
</body>
</html>
When events are invoked as part of the event flow the
this value will remain the value of the node or object that the
event listener is attached too. In the code below we add a
click event listener to the <body> and
regardless of if you click on the <div> or the
<body> the value of this always points to
<body>.
<!DOCTYPE html>
<html lang="en">
<body>
<div>click me</div>
<script>
//click on the <div> or the <body> the value of this remains the <body> element node
document.body.addEventListener('click',function(){
console.log(this); //log <body>...</body>
},false);
</script>
</body>
</html>
Additionally its possible using the
event.currentTarget property to get the same reference, to the
node or object invoking the event listener, that the
this property provides. In the code below I leverage the
event.currentTarget
event object property showcasing that it returns the same value as
this.
11.8 Referencing the target of an event and not the node or
object the event is invoked on
Because of the event flow its possible to click a <div>,
contained inside of a <body> element and have a
click event listener attached to the
<body> element get invoked. When this happens, the event
object passed to the event listener function attached to the
<body> provides a reference (i.e. event.target)
to the node or object that the event originated on (i.e. the target). In
the code below when the <div> is clicked, the
<body> element's click event listener is invoked
and the event.target property references the orginal
<div> that was the target of the click event. The
event.target can be extremely useful when an event that fires
because of the event flow needs knowledge about the origin of the event.
<!DOCTYPE html>
<html lang="en">
<body>
<div>click me</div>
<script>
document.body.addEventListener('click',function(event){
//when the <div> is clicked logs '<div>' because the <div> was the target in the event flow
console.log(event.target);
},false);
</script>
</body>
</html>
Consider that in our code example if the <body> element
is clicked instead of the <div> then the event
target and the element node that the event listener is invoked
on are the same. Therefore event.target, this, and
event.currentTarget will all contain a reference to the
<body> element.
11.9 Cancelling default browser events using preventDefault()
Browsers provide several events already wired up when an HTML page is
presented to a user. For example, clicking a link has a corresponding
event (i.e. you navigate to a url). So does clicking a checkbox (i.e.
box is checked) or typing text into a text field (i.e. text is inputed
and appears on screen). These browser events can be prevented by calling
the preventDefault() method inside of the event handler
function associated with a node or object that invokes a browser default
event. In the code below I prevent the default event that occurs on a
<a>, <input>, and
<textarea>.
<!DOCTYPE html>
<html lang="en">
<body>
<a href="google.com">no go</div>
<input type="checkbox" />
<textarea></textarea>
<script>
document.querySelector('a').addEventListener('click',function(event){
event.preventDefault(); //stop the default event for <a> which would be to load a url
},false);
document.querySelector('input').addEventListener('click',function(event){
event.preventDefault(); //stop default event for checkbox, which would be to toggle checkbox state
},false);
document.querySelector('textarea').addEventListener('keypress',function(event){
event.preventDefault(); //stop default event for textarea, which would be to add characters typed
},false);
/*keep in mind that events still propagate, clicking the link in this html document will stop the default event but not event bubbling*/
document.body.addEventListener('click',function(){ console.log('the event flow still flows!'); },false);
</script>
</body>
</html>
All attempts to click the link, check the box, or type in the text input
in the previous code example will fail because I am preventing the
default events for these elements from occuring.
Notes
The preventDefault() methods does not stop events from
propagating (i.e. bubbling or capture phases)
Providing a return false at the end of the body of the event
listener has the same result as call the
preventDefault() method
The event object passed to event listener functions contains a boolean
cancelable property which indicates if the event will respond
to preveentDefault() method and canceling default behavior
The event object passed to event listener functions contains a
defaultPrevented property which indicates true if
preventDefault() has been invoked for a bubbling event.
11.10 Stoping the event flow using stopPropagation()
Calling stopProgagation() from within an event handler/listener
will stop the capture and bubble event flow phases, but any events
directly attached to the node or object will still be invoked. In the
code below the onclick event attached to the
<body> is never gets invoked because we are stopping the
event from bubbling up the DOM when clicking on the
<div>.
<!DOCTYPE html>
<html lang="en">
<body>
<div>click me</div>
<script>
document.querySelector('div').addEventListener('click',function(){
console.log('me too, but nothing from the event flow!');
},false);
document.querySelector('div').addEventListener('click',function(event){
console.log('invoked all click events attached, but cancel capture and bubble event phases');
event.stopPropagation();
},false);
document.querySelector('div').addEventListener('click',function(){
console.log('me too, but nothing from the event flow!');
},false);
/*when the <div> is clicked this event is not invoked because one of the events attached to the <div> stops the capture and bubble flow.*/
document.body.addEventListener('click',function(){ console.log('What, denied from being invoked!'); },false);
</script>
</body>
</html>
Notice that other click events attached to the the
<div> still get invoked! Additionally using
stopPropagation() does not prevent default events. Had the
<div> in our code example been a <a> with
an href value calling stopPropagation would not have stopped the browser
default events from getting invoked.
11.11 Stoping the event flow as well as other like events on the same
target using stopImmediatePropagation()
Calling the stopImmediatePropagation() from within an event
handler/listener will stop the event flow phases (i.e.
stopPropagation()), as well as any other like events attached
to the event target that are attached after the event listener that
invokes the stopImmediatePropagation() method. In the code
example below If we call stopImmediatePropagation()from the
second event listener attached to the <div> the click
event that follows will not get invoked.
<!DOCTYPE html>
<html lang="en">
<body>
<div>click me</div>
<script>
//first event attached
document.querySelector('div').addEventListener('click',function(){
console.log('I get invoked because I was attached first');
},false);
//seond event attached
document.querySelector('div').addEventListener('click',function(event){
console.log('I get invoked, but stop any other click events on this target');
event.stopImmediatePropagation();
},false);
//third event attached, but because stopImmediatePropagation() was called above this event does not get invoked
document.querySelector('div').addEventListener('click',function(){
console.log('I get stopped from the previous click event listener');
},false);
//notice that the event flow is also cancelled as if stopPropagation was called too
document.body.addEventListener('click',function(){ console.log('What, denied from being invoked!'); },false);
</script>
</body>
</html>
Notes
Using the stopImmediatePropagation() does not prevent default
events. Browser default events still get invoked and only calling
preventDefault() will stop these events.
11.12 Custom events
A developer is not limited to the predefined event types. Its possible
to attach and invoke a custom event, using the
addEventListener() method like normal in combiniation with
document.createEvent(), initCustomEvent(), and
dispatchEvent(). In the code below I create a custom event
called goBigBlue and invoke that event.
//create the custom event var cheer = document.createEvent('CustomEvent'); //the 'CustomEvent' parameter is required
//create an event listener for the custom event divElement.addEventListener('goBigBlue',function(event){ console.log(event.detail.goBigBlueIs) },false);
/*Use the initCustomEvent method to setup the details of the custom event.
Parameters for initCustomEvent are: (event, bubble?, cancelable?, pass values to event.detail)*/ cheer.initCustomEvent('goBigBlue',true,false,{goBigBlueIs:'its gone!'}); //invoke the custom event using dispatchEvent divElement.dispatchEvent(cheer);
</script>
</body>
</html>
Notes
IE9 requires (not optinal) the fourth parameter on
initiCustomEvent()
Simiulating an event is not unlike creating a custom event. In the case
of simulating a mouse event we create a 'MouseEvent' using
document.createEvent(). Then, using
initMouseEvent() we setup the mouse event that is going to
occur. Next the mouse event is dispatched on the element that we'd like
to simulate an event on (i.e the <div> in the html
document). In the code below a click event is attached to the
<div> in the page. Instead of clicking the
<div> to invoke the click event the event is triggered or
simulated by programatically setting up a mouse event and dispatching
the event to the <div>.
<!DOCTYPE html>
<html lang="en">
<body>
<div>no need to click, we programatically trigger it</div>
<script>
var divElement = document.querySelector('div');
//setup click event that will be simulated divElement.addEventListener('click',function(event){ console.log(Object.keys(event)); },false);
Simulating/triggering mouse events as of this writing works in all
modern browsers. Simulating other event types quickly becomes more
complicated and leveraging
simulate.js or
jQuery (e.g. jQuery trigger() method) becomes neccsary.
11.14 Event delegation
Event delegation, stated simply, is the programmatic act of leveraging
the event flow and a single event listener to deal with multiple event
targets. A side effect of event delegation is that the event targets
don't have to be in the DOM when the event is created in order for the
targets to respond to the event. This is of course rather handy when
dealing with XHR responses that update the DOM. By implementing event
delegation new content that is added to the DOM post JavaScript load
parsing can immediately start responding to events. Imagine you have a
table with an unlimited number of rows and columns. Using event
delegation we can add a single event listener to the
<table> node which acts as a delegate for the node or
object that is the initial target of the event. In the code example
below, clicking any of the <td>'s (i.e. the target of the
event) will delegate its event to the click listener on the
<table>. Don't forget this is all made possible because
of the event flow and in this specific case the bubbling phase.
<!DOCTYPE html>
<html lang="en">
<body>
<p>Click a table cell</p>
<table border="1"> <tbody> <tr><td>row 1 column 1</td><td>row 1 column 2</td></tr> <tr><td>row 2 column 1</td><td>row 2 column 2</td></tr> <tr><td>row 3 column 1</td><td>row 3 column 2</td></tr> <tr><td>row 4 column 1</td><td>row 4 column 2</td></tr> <tr><td>row 5 column 1</td><td>row 5 column 2</td></tr> <tr><td>row 6 column 1</td><td>row 6 column 2</td></tr> </tbody> </table>
<script>
document.querySelector('table').addEventListener('click',function(event){
if(event.target.tagName.toLowerCase() === 'td'){ //make sure we only run code if a td is the target console.log(event.target.textContent); //use event.target to gain access to target of the event which is the td
} },false);
</script>
</body>
</html>
If we were to update the table in the code example with new rows, the
new rows would responded to the click event as soon as they
were render to the screen because the click event is delegated to the
<table> element node.
Notes
Event delegation is ideally leverage when you are dealing with a
click, mousedown, mouseup,
keydown, keyup, and keypress event type.
Chapter 12 - Creating dom.js - a wishful jQuery inspired DOM Library for
modern browers
12.1 dom.js overview
I want you to take the information and knowledge from this book and
leverage it as I walk you through a foundation for a wishful, modern,
jQuery like DOM library called dom.js. Think of dom.js as the foundation
to a modern library for selecting DOM nodes and doing something with
them. Not unlike jQuery the dom.js code will provide a function for
selecting something from the DOM (or creating) and then doing something
with it. I show some examples of the dom() function below which
shouldn't look all that foreign if you are familiar with jQuery or
really any DOM utility for selecting elements.
//select in a document all li's in the first ul and get the innerHTML for the first li
dom('li','ul').html();
//create html structure using a document fragment and get the innerHTML of ul
dom('<ul><li>hi</li></ul>').html()
For most readers this chapter is simply an exercise in taking the
information in this book and applying it to a JavaScript DOM library.
For others, this might just shed some light on jQuery itself and any DOM
manipulation logic used in JavaScript frameworks today. Ideally, in the
end, I hope this exercise inspires readers to craft their own micro DOM
abstractions on an as needed bases when the situation is right. With
that said, lets begin.
12.2 Create a unique scope
To protect our dom.js code from the global scope, I will first create a
unique scope to which it can live and operate within without fear of
collisions in the global scope. In the code below I setup a pretty
standard
Immediately-Invoked Function Expression
to create this private scope. When the IIFE is invoked the value of
global will be set to the current global scope (i.e.
window).
(function(win){
var global = win; var doc = this.document;
}}(window);
Inside of the IIFE we setup a reference to the window and
document object (i.e. doc) to speed up the access to
these objects inside of the IIFE.
12.3 Create the dom() and GetOrMakeDom() functions
exposing dom() and GetOrMakeDom.prototype to the
global scope
Just like jQuery we are going to create a function that will return a
chain-able, wrapped set (i.e. custom array like object) of DOM nodes
(e.g. {0:ELEMENT_NODE,1:ELEMENT_NODE,length:2}) based on the
parameters sent into the function. In the code below I setup the
dom() function and parameters which get passed on to the
GetOrMakeDOM constructor function that when invoked will return
the object containing the DOM nodes, that is then returned by from
dom().
(function(win){
var global = win; var doc = global.document;
var dom = function(params,context){
return new GetOrMakeDom(params,context);
};
var GetOrMakeDom = function(params,context){
};
})(window);
In order for the dom() function to be accessed/called from
outside of the private scope setup by the IIFE we have to expose the dom
function (i.e. create a reference) to the global scope. This is done by
creating a property in the global scope called dom and pointing
that property to the local dom() function. When dom is
accessed from the global scope it will point to my locally scoped
dom() function. In the code below doing,
global.dom = dom; does the trick.
(function(win){
var global = win; var doc = global.document;
var dom = function(params,context){
return new GetOrMakeDom(params,context);
};
var GetOrMakeDom = function(params,context){
};
//expose dom to global scope global.dom = dom;
})(window);
The last thing we need to do is expose the
GetOrMakeDom.prototype property to the global scope. Not unlike
jQuery (e.g. jQuery.fn) we are simply going to provide a
shortcut reference from dom.fn to
GetOrMakeDOM.prototype. This is shown in the code below.
(function(win){
var global = win; var doc = global.document;
var dom = function(params,context){
return new GetOrMakeDom(params,context);
};
var GetOrMakeDom = function(params,context){
};
//expose dom to global scope global.dom = dom;
//short cut to prototype dom.fn = GetOrMakeDom.prototype;
})(window);
Now anything attached to the dom.fn is actually a property of
the GetOrMakeDOM.prototype object and is inherited during
property lookup for any object instance created from the
GetOrMakeDOM constructor function.
Notes
The getOrMakeDom function is invoked with the
new operator. Make sure you
understand
what happens when a function is invoked using the
new operator.
12.4 Create optional context paramater passed to dom()
When dom() is invoked, it also invokes the
GetOrMakeDom function passing it the parameters that are sent
to dom(). When the GetOrMakeDOM constructor is invoked
the first thing we need to do is determine context. The context for
working with the DOM can be set by passing a selector string used to
select a node or a node reference itself. If its not obvious the purpose
of passing a context to the dom() function provides the ability
to limit the search for element nodes to a specific branch of the DOM
tree. This is very similar, almost identical, to the second parameter
passed to the jQuery or $ function. In the code below
I default the context to the current document found in the global scope.
If a context parameter is available, I determine what it is (i.e. string
or node) and either make the node passed in the context or select a node
via querySelectorAll().
(function(win){
var global = win; var doc = global.document;
var dom = function(params,context){
return new GetOrMakeDom(params,context);
};
var GetOrMakeDom = function(params,context){
var currentContext = doc;
if(context){
if(context.nodeType){//its either a document node or element node
currentContext = context;
}else{ //else its a string selector, use it to selector a node
currentContext = doc.querySelector(context);
}
}
};
//expose dom to global scope global.dom = dom;
//short cut to prototype dom.fn = GetOrMakeDom.prototype;
})(window);
With the context parameter logic setup we can next add the
logic required to deal with the params parameter used to
actually select or created nodes.
12.5 Populate object with DOM node references based on
params and return object
The params parameter passed to dom(), then on to the
getOrMakeDom() varies in the type of parameter that can be
passed. Similar to jQuery the type's of value's passed can be any one of
the following:
css selector string (e.g. dom('body'))
html string (e.g.
dom('<p>Hellow</p><p> World!</p>'))
Element node (e.g. dom(document.body))
array of element nodes (e.g. dom([document.body]))
a NodeList (e.g. dom(document.body.children))
a HTMLcollection (e.g. dom(document.all))
a dom() object itself. (e.g. dom(dom()))
The result of passing params is the construction of a
chain-able object containing references to nodes (e.g.
{0:ELEMENT_NODE,1:ELEMENT_NODE,length:2}) either in the DOM or
in a document fragment. Lets examine how each of the above parameters
can be used to produce an object containing node references.
The logic to permit such a wide variety of parameter types is shown
below in the code and starts with a simple check to verify that
params is not undefined, an empty string, or a string
with empty spaces. If this is the case we add a length property
with a value of 0 to the object constructed from calling
GetOrMakeDOM and return the object so the execution of the
function ends. If params is not a false (or false like) value the execution of the function continues.
Next the params value, if a string, is checked to see if
contains HTML. If the string contains HTML then a
document fragment is created and the string is used as the innerHTML value for
a <div> contained in the document fragment so that the
string is converted to a DOM structure. With the html string converted
to a node tree, the structure is looped over accessing top level nodes,
and references to these nodes are passed to the object being created by
GetOrMakeDom. If the string does not contain HTML execution of
the function continues.
The next check simply verifies if params is a reference to a
single node and if it is we wrap a reference to it up in an object and
return it other wise at we are pretty sure the params value is
a
html collection,
node list, array, string
selector, or
an object created from dom(). If its a string selector, a node
list is created by calling the queryselectorAll() method on the
currentContext. If its not a string selector we loop over the
html collection, node list, array, or object extracting the node
references and using the references as values contained in the object
sent back from calling the GetOrMakeDom.
All of this logic inside of GetOrMakeDom() function can be a
bit overwhelming just realize that the point of the constructor function
is to construct an object containing references to nodes (e.g.
{0:ELEMENT_NODE,1:ELEMENT_NODE,length:2}) and returns this
object to dom().
(function(win){
var global = win; var doc = global.document;
var dom = function(params,context){
return new GetOrMakeDom(params,context);
};
var regXContainsTag = /^\s*<(\w+|!)[^>]*>/;
var GetOrMakeDom = function(params,context){
var currentContext = doc;
if(context){
if(context.nodeType){
currentContext = context;
}else{
currentContext = doc.querySelector(context);
}
}
//if no params, return empty dom() object
if(!params || params === '' || typeof params === 'string' && params.trim() === ''){
this.length = 0;
return this;
}
//if HTML string, construct domfragment, fill object, then return object
if(typeof params === 'string' && regXContainsTag.test(params)){//yup its forsure html string
//create div & docfrag, append div to docfrag, then set its div's innerHTML to the string, then get first child
var divElm = currentContext.createElement('div');
divElm.className = 'hippo-doc-frag-wrapper';
var docFrag = currentContext.createDocumentFragment();
docFrag.appendChild(divElm);
var queryDiv = docFrag.querySelector('div');
queryDiv.innerHTML = params;
var numberOfChildren = queryDiv.children.length;
//loop over nodelist and fill object, needs to be done because a string of html can be passed with siblings
for (var z = 0; z < numberOfChildren; z++) {
this[z] = queryDiv.children[z];
}
//give the object a length value
this.length = numberOfChildren;
//return object
return this; //return e.g. {0:ELEMENT_NODE,1:ELEMENT_NODE,length:2}
}
//if a single node reference is passed, fill object, return object
if(typeof params === 'object' && params.nodeName){
this.length = 1;
this[0] = params;
return this;
}
//if its an object but not a node assume nodelist or array, else its a string selector, so create nodelist
var nodes;
if(typeof params !== 'string'){//nodelist or array
nodes = params;
}else{//ok string
nodes = currentContext.querySelectorAll(params.trim());
}
//loop over array or nodelist created above and fill object
var nodeLength = nodes.length;
for (var i = 0; i < nodeLength; i++) {
this[i] = nodes[i];
}
//give the object a length value
this.length = nodeLength;
//return object
return this; //return e.g. {0:ELEMENT_NODE,1:ELEMENT_NODE,length:2}
};
//expose dom to global scope global.dom = dom;
//short cut to prototype dom.fn = GetOrMakeDom.prototype;
})(window);
12.6 Create each() method and make it a chainable method
When we invoke dom() we can access anything attached to
dom.fn by way of prototypical inheritance. (e.g.
dom().each()). Not unlike jQuery methods attached to
dom.fn operate on the object created from the
GetOrMakeDom constructor function. The code below setups the
each() method.
dom.fn.each = function (callback) { var len = this.length; //the specific instance create from getOrMakeDom() and returned by calling dom() for(var i = 0; i < len; i++){
//invoke the callback function setting the value of this to element node and passing it parameters callback.call(this[i], i, this[i]); } };
As you might expect the each() method takes a callback function
as a parameter and invokes the function (setting the this value
to the element node object with call()) for each node element
in the getOrMakeDom object instance. The this value
inside of the each() function is a reference to the
getOrMakeDom object instance (e.g.
{0:ELEMENT_NODE,1:ELEMENT_NODE,length:2}).
When a method does not return a value (e.g.
dom().length returns a length) its possible to allow method
chaning by simply returning the object the method belongs too instead of
a specific value. Basically, we are returning the
GetOrMakeDom object so another method can be called on this
instance of the object. In the code below I would like the
each() method to be chainable, meaning more methods can be
called after calling each(), so I simply return this.
The this in the code below is the object instance created from
calling the getOrMakeDom function.
dom.fn.each = function (callback) { var len = this.length; for(var i = 0; i < len; i++){ callback.call(this[i], i, this[i]); }
return this; //make it chainable by returning e.g. {0:ELEMENT_NODE,1:ELEMENT_NODE,length:2} };
12.7 Create html(), append(), &
text() methods
With the core each() method created and implicit iteration
avaliable we can now build out a few dom() methods that act on
the nodes we select from an HTML document or create using document
fragments. The three methods we are going to create are:
The html() and text() methods follow a very similar
pattern. If the method is called with a parameter value we loop (using
dom.fn.each() for implicit iteration ) over each element node
in the getOrMakeDom object instance setting either the
innerHTML value or textContent value. If no parameter
is sent we simply return the innerHTML or
textContent value for the first element node in the
getOrMakeDom object instance. Below you will see this logic
coded.
dom.fn.html = function(htmlString){
if(htmlString){
return this.each(function(){ //notice I return this so its chainable if called with param
this.innerHTML = htmlString;
});
}else{
return this[0].innerHTML;
}
};
dom.fn.text = function(textString){
if(textString){
return this.each(function(){ //notice I return this so its chainable if called with param
this.textContent = textString;
});
}else{
return this[0].textContent.trim();
}
};
The append() method leveraging insertAdjacentHTML will
take a an html string, text string, dom() object, nodelist/HTML
collection a single node or array of nodes and appends it to the nodes
selected.
This chapter has been about creating a foundation to a jQuery like DOM
library. If you'd like to continue studying the building blocks to a
jQuery-like DOM library I would suggest checking out
hippo.js, which is
an exercise in re-creating the jQuery DOM methods for modern browsers.
Both dom.js and
hippo.js make use
of grunt,
QUnit, and
JS Hint which I highly recommend
looking into if building your own JavaScript libraries is of interest.
In addition to the fore mentioned developer tools I highly recommending
reading, "Designing Better JavaScript APIs". Now go build something for the DOM.